High speed video transcoding in the cloud.
Transcode your videos at lightning speed.


Transcode your videos at lightning speed.
Output to a variety of supported resolutions in just a few clicks.
Bento is a blazing fast serverless video transcoding pipeline that can be easily deployed to Amazon Web Services (AWS). It is built for individuals and small businesses seeking a fast, simple, open-source solution to their video transcoding needs.
Converting high-definition videos to new formats and resolutions is a process that can take hours on a single machine. By leveraging the instant scale and concurrent execution of Function as a Service architecture, Bento transcodes hundreds of small parts of a video file in parallel, slashing multi-hour transcoding jobs down to minutes.
This case study will outline the approach that we took to developing a serverless solution to video transcoding, and benchmark Bento against competing solutions to demonstrate the impressive results yielded by this approach. We will conclude by discussing the technical challenges of processing large video files in a highly concurrent cloud system.
To begin, let’s take a step back and discuss what video transcoding is, and why video is among the most compelling challenges in web development.
Video-on-demand platforms are billion-dollar businesses. Video dominates social media feeds and internet ads. Yet for all of this, video is often taken for granted. We rarely stop to consider how video is unique among web content.
For one, video is ubiquitous. This year, video is projected to make up 79% of all internet traffic. With new video-based services and apps launching seemingly every day, video traffic is predicted to grow to over 82% of total internet traffic within the next few years.
Video is also distinct from most other web traffic because video files tend to be very large; they are usually an order of magnitude larger than images. As a result, video tends to present challenges related to storage, memory, and bandwidth that other types of resources don’t present. In addition, the size of video files is increasing as advancing video technologies allow for higher resolutions and higher frame rates. As a result, these challenges are expected to grow.

Finally, video is complex. Delivering video files over the internet is more complicated than perhaps any other file type. The source of this complexity comes from two major challenges: the compatibility problem and the bandwidth problem. We will delve into these two problems as an introduction to video transcoding and why it is necessary.
To discuss the problems surrounding compatibility and bandwidth, we must first explain what a video file is.
When a video is first recorded by a phone or camera, the raw video data is too large to store locally, much less send over the web. For example, an hour of 1080p 60fps uncompressed video is around 1.3 terabytes.
To bring the size of this raw data down to a more manageable size, the data must be compressed. The software that is used to compress this data is called a codec (a combination of the words coder and decoder). A codec applies an algorithm to compress video data, encoding it so that it can be easily stored and sent. Once compressed, the data is packaged into a file format, called a container. Containers have extensions you may have seen, like .mp4 or .mov.
When playing a video this process is reversed. A media player opens the container, and the same codec is used to decode the video data and display it on the device.
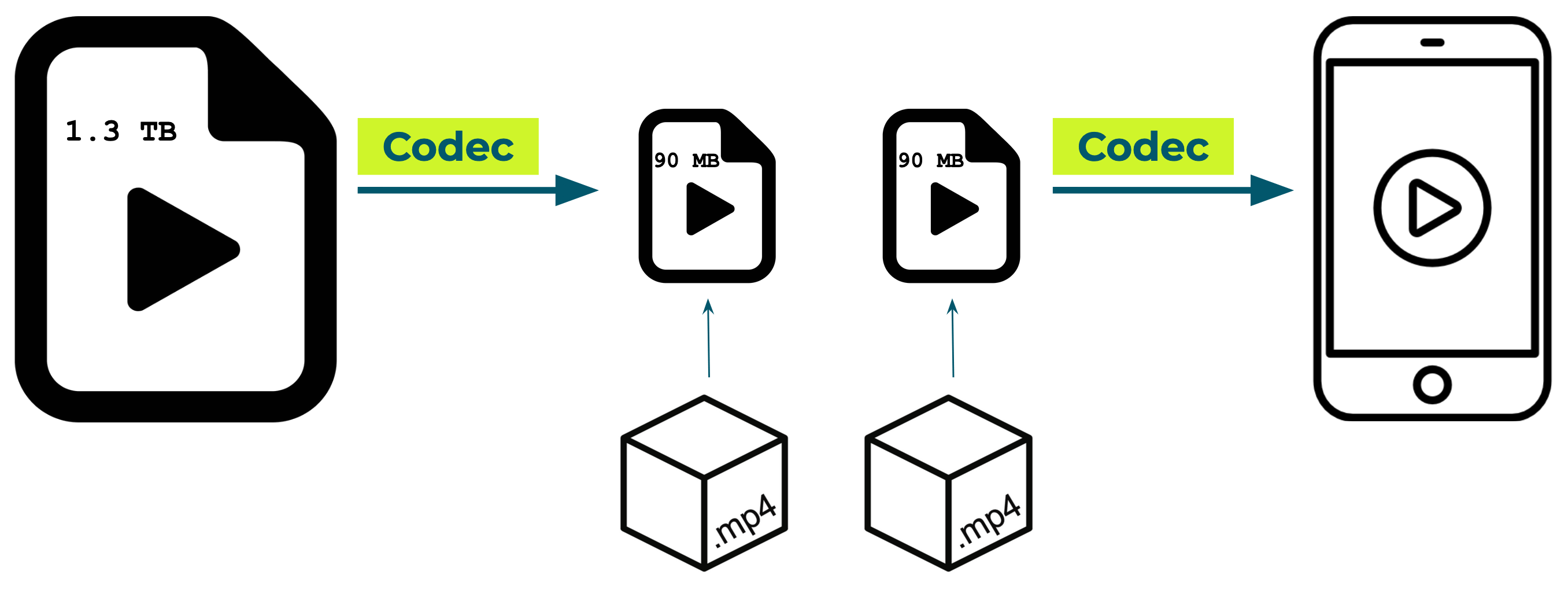
Encoded videos are decoded with the same codec for playback
The first problem that businesses face is that there are dozens of different codecs, containers, and video players, each with their own strengths and weaknesses. Unfortunately, they are not all compatible with each other. Using the wrong codec or container could mean that some users can’t play certain videos on their device. Therefore a decision must be made as to which codec and container will be used to package a video.
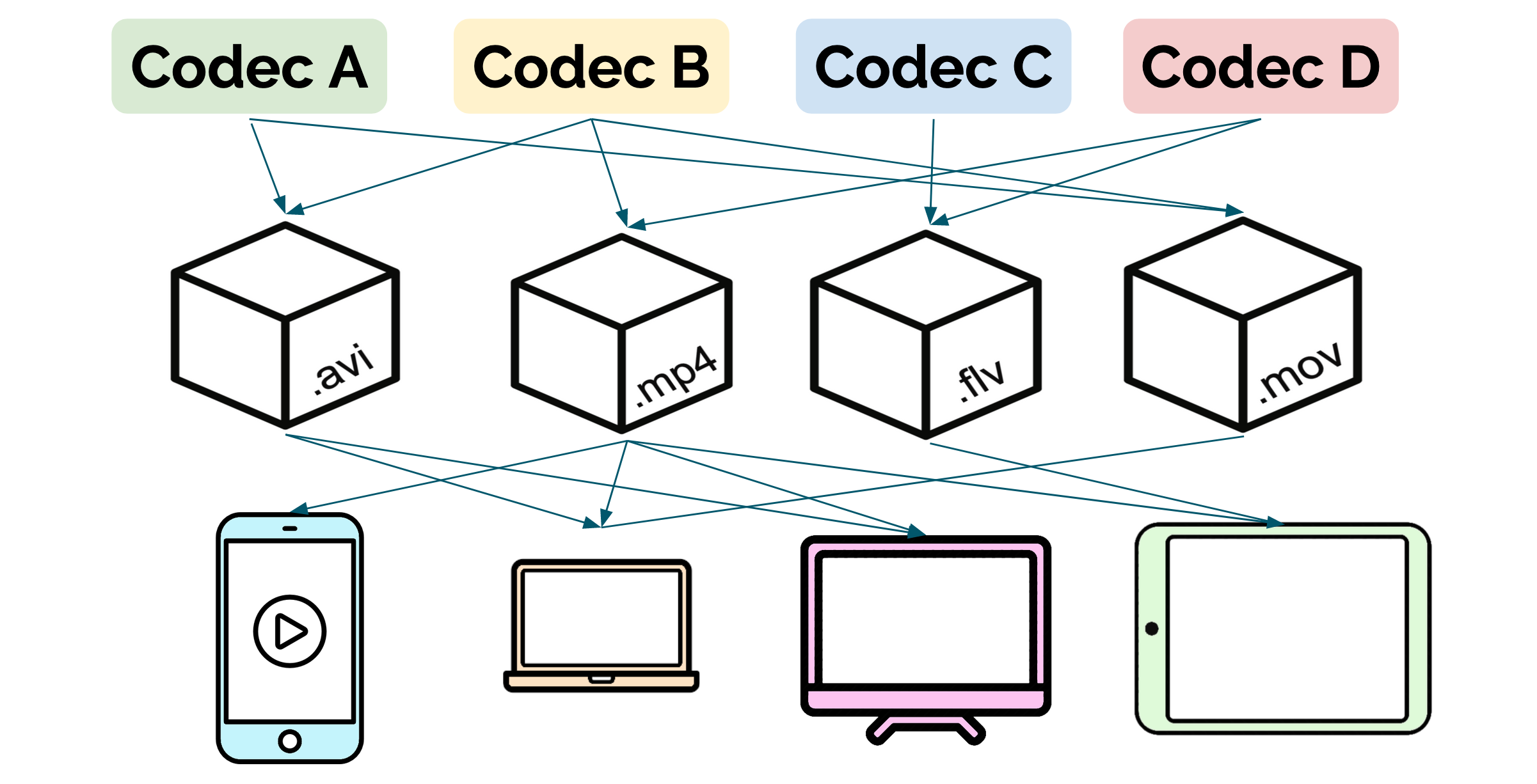
Usually this decision will be made based on the characteristics of the codec and the types of devices or media players that a business expects their users to have. Once they have made this decision, they need to convert any video files they have using the codec and container they have decided on.
Businesses select a codec and container format to optimize compatibility
However, now they need to answer a second question: how much should they compress their videos?
Generally speaking, there is a negative correlation between the level of compression and the quality of the resultant video. The more a video file is compressed, the greater the decrease in visual fidelity. This means that the less a video is compressed, the more of its original quality is preserved and the larger the file size. However, not all users will have the bandwidth to quickly download larger, higher quality files.

Higher levels of compression diminish video quality.
1080p (top) vs 360p (bottom)
Consider for instance, the difference in download speed that will be available to a user on a fiber internet connection in their office, and a user on 3G mobile connection going through a subway tunnel as they both attempt to download the same video. The person in their office will have a smooth experience, whereas the person in the tunnel may have a choppy experience, if their video plays at all.
For this reason, businesses will usually create multiple versions of the same video at different rates of compression, and thus different file sizes. Modern media players detect users’ bandwidth, and deliver the video file most appropriate for speed of their connection. Smaller, more compressed videos will be delivered to users with less available bandwidth, while users with stronger connections will be served higher quality videos.
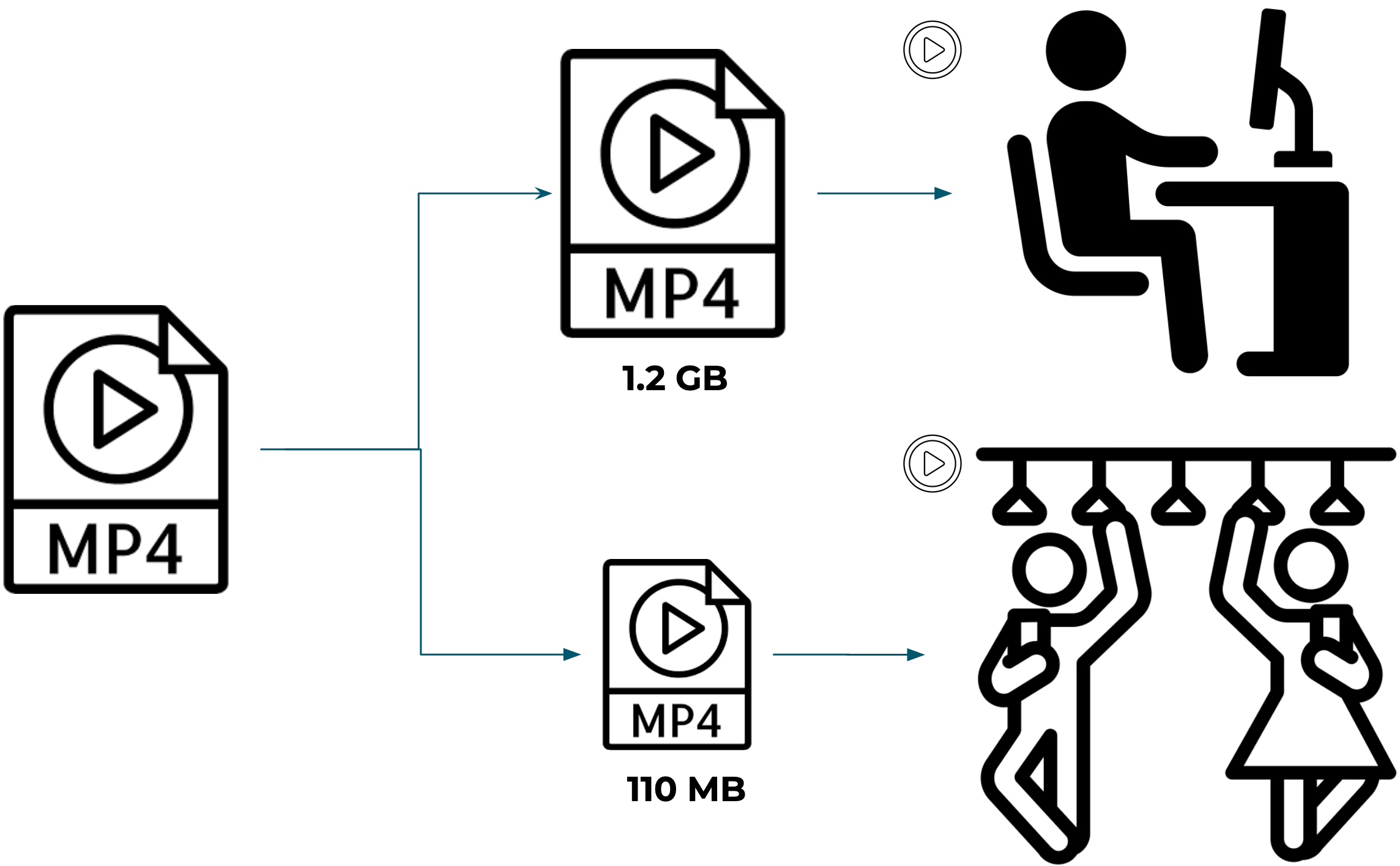
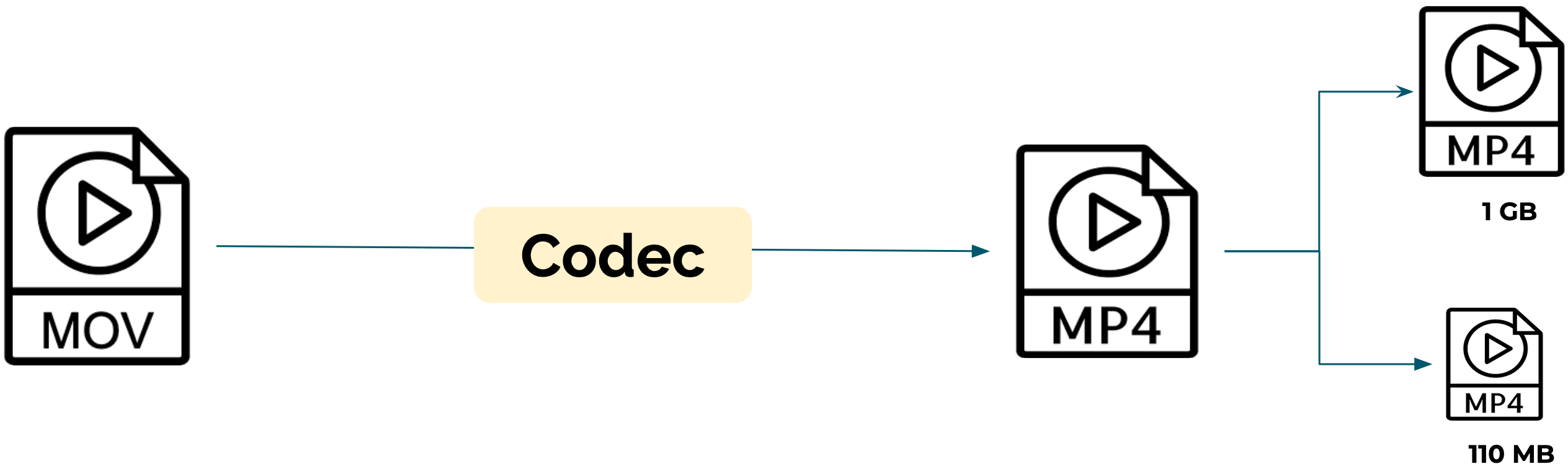
To recap, businesses that deliver video will use a codec to convert their videos into a single container format, compressed to multiple file sizes.
This process of conversion is called video transcoding. The process of ingesting a video file and transcoding it to specific formats and file sizes is coordinated and facilitated by a transcoding pipeline.
Every business that delivers video files on the internet will consider how they are going to handle this process of transcoding their videos. Unfortunately, the video transcoding process possesses its own inherent challenges that need to be addressed when negotiating a transcoding solution.
First, transcoding large video files takes a very long time. Transcoding a single 60 minute HD video can take anywhere from two to six hours, and sometimes more.
Second, transcoding is demanding on memory and CPU. A video transcoding process will happily eat all the CPU and memory that are thrown at it.
Transcoding on a single local machine may be a viable option for individuals that only transcode a few videos per month. However, businesses that have regular video demand will not find this to be a feasible option, and will generally choose between one of two professional transcoding solutions.
Broadly considered, professional video transcoding solutions will fall into two categories: customized solutions that are developed and maintained in-house and third party commercial software.

Some businesses choose to build their own video transcoding farm in-house. In this case, a development team is needed to build custom transcoding pipeline and deploy it to bare metal servers or cloud infrastructure (e.g. Amazon EC2, Digital Ocean Droplet).
Once deployed, this option is cheaper than third-party software, and it provides businesses with maximum control over what formats, codecs, and video settings they support, as well as any additional transformations they want to make to their videos.
This option requires a high amount of technical expertise both to develop and scale effectively: video transcoding can be both slow and error prone without significant engineering attention. As we’ll see later, provisioning servers for video transcoding can also result in periods wherein compute power is going unused.
Building a custom transcoding farm is best-suited for video platforms such as Netflix and YouTube. Companies that ingest and stream millions of hours of video each week can build their own engineering operations around this task to minimize the trade-offs.

A second solution is to use commercial video transcoding software. Services such as Amazon MediaConvert and Zencoder offer powerful cloud-based transcoding.
These services provide comprehensive solutions for businesses that need to support multiple formats, codecs, and devices. Because these services specialize in video, they will be tuned for speed and adept at handling the error cases that typically accompany transcoding jobs.
However, the number of transcoding options many of these services provide may be overkill for smaller businesses that have fewer input and output requirements. And, as one might expect, these services tend to be a more expensive option.
Transcoding services are a good fit for media production companies (e.g. HBO, BBC) that produce massive amounts of video content that lands on many devices, and don’t want to build large software engineering teams around video transcoding.
Let’s briefly review the options outlined above.
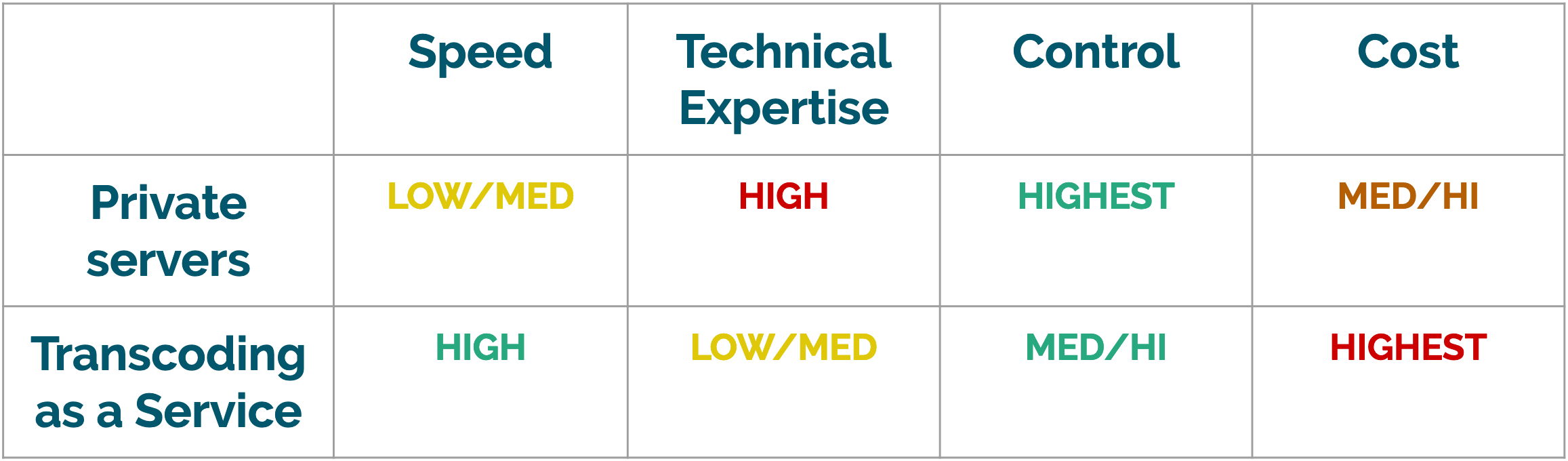
Custom pipelines provide the highest level of control over inputs and outputs. The bottleneck is technical expertise - to really get the best performance and cost from this model, a business needs to build a dedicated software engineering team around video transcoding.
By contrast, businesses can outsource their video transcoding to third-party services. These services provide the benefits of speed and control, but at a higher cost.
These options are sufficient for some businesses, but the Bento team saw an opportunity here. Is it possible to build a fast, low-cost transcoding pipeline, suited for businesses that don’t have video expertise and won’t need a plethora of video options?
We felt that the answer was yes, and that the solution might lie in serverless technology.
Bento is a “serverless” transcoding pipeline, but what does that mean? As it turns out, serverless is a bit of an overloaded term and it’s not always clear what exactly is being referred to.
Serverless originally referred to applications that would outsource business-logic and state management to third party services.
Here, a robust client application interacts with a cloud-hosted backend that is implemented by some third party. This kind of architecture is sometimes called Backend as a Service (BaaS). You, as the developer, create a client side application and the BaaS provides functionality like storage, caching, and authentication via an API.
These days, however, serverless usually refers to a related but distinct architecture called Function as a Service, or FaaS.
Function as a Service (FaaS) is similar to BaaS in that both abstract away the details of infrastructure scaling and management.
However, in contrast to BaaS, developers are responsible for implementing their backend code. The most significant distinction comes from how this code is deployed and executed:
In a FaaS architecture, application code is executed in short-lived compute containers that run in response to an event.
Let’s dissect that statement. The key characteristics of Function as a Service are:
As a consequence of these characteristics, FaaS architecture does not require long running servers or applications. A function’s container will only run for the time it takes the function to complete. Developers simply write code and upload it to a cloud server, knowing that their code will execute when a specific event occurs.
Cloud computing services like Amazon Web Services, Google Cloud Platform, and Microsoft Azure offer their own FaaS platforms (AWS Lambda, Cloud Functions, and Azure Functions, respectively). These platforms provision the necessary application environment and computing resources to run the provided code, and handle the scaling of function instances as needed.

Function as a Service provides a number of benefits over traditional long-lived server architectures.
The first benefit is core to serverless computing as a whole, which is the delegation of infrastructure management to a third-party. In particular, FaaS enables developers to write and quickly deploy application code while concerns around resource provisioning, execution environment, and availability are delegated to the FaaS provider.
Function as a service can be cost efficient for certain types of workflows, as developers are not charged for idle server time. Instead, billing is related to compute time which starts when a function is triggered by an event and ends when the function’s code execution is complete. Compute time can be calculated in increments as small as 100 milliseconds. This means that short-duration processes that run intermittently can see a significant reduction in cost relative to running on a persistent server.
The most important features of FaaS in the context of Bento’s architecture are the automated scaling and concurrent execution of function containers. Combined, these two features enable us to execute hundreds of transcoding jobs in parallel, within seconds.
These behaviors are really the bread and butter of Bento, and we will dive into them more deeply in a short while. Before we do that, let’s consider the tradeoffs of building with FaaS.
Function as a Service also presents drawbacks and challenges in relation to traditional server architecture.
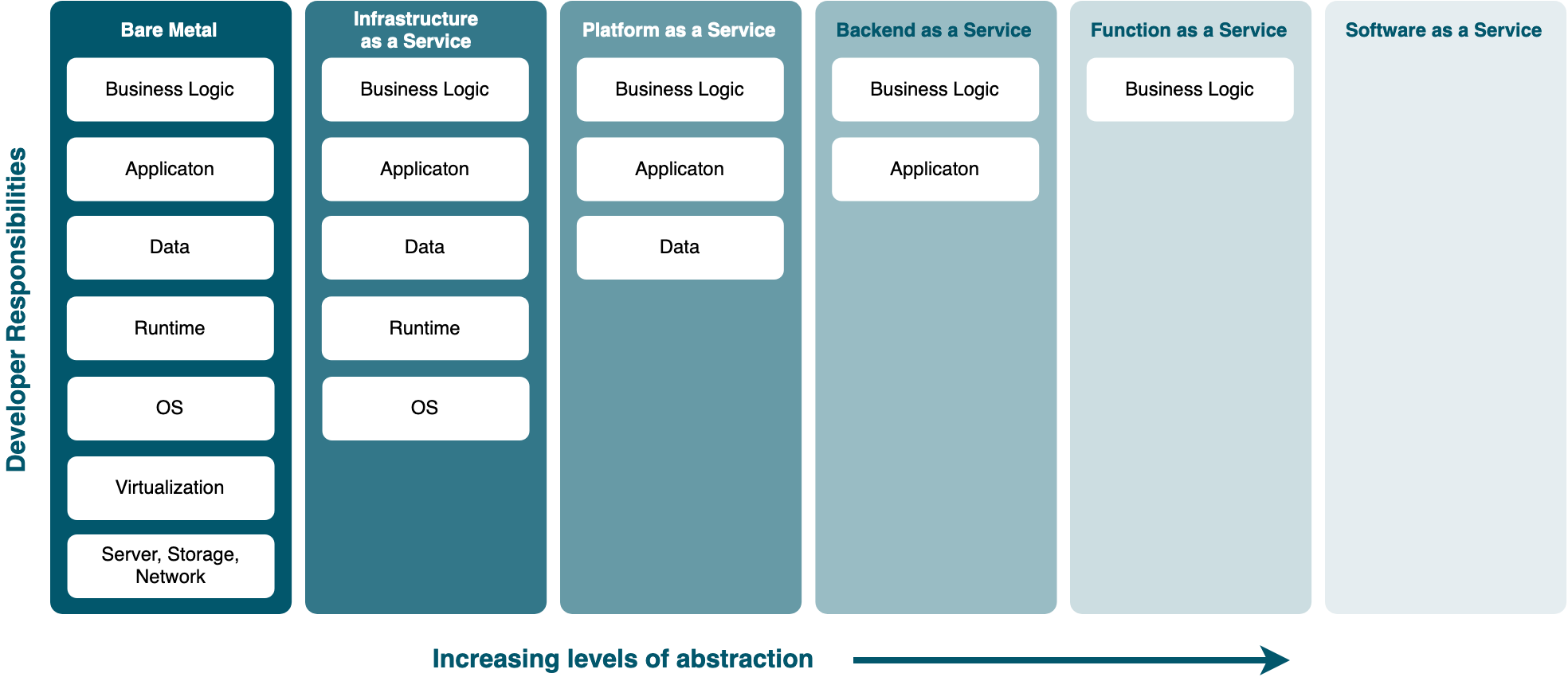
Function as a Service exists on a spectrum of infrastructure solutions that are intended to abstract away an increasing amount of administration, configuration, and maintenance responsibilities that exist alongside any scalable web application.
The tradeoff of this reduction in responsibilities is a loss of control over the choices made at each level of abstraction.
For example, developers deploying an application to bare metal servers must account for every part of the software stack, all the way down to hardware selection. Infrastructure as a Service (IaaS) abstracts away hardware concerns, leaving developers responsible for setting up the entire runtime environment including the operating system.
On the other end of the abstraction spectrum are solutions like Backend as a Service, which abstract away server-side implementation entirely and simply provide an API to interact with the service. At this end, most choices are made by the providers of the service - developers have little, if any, control over implementation details.
Function as a Service sits closer to this end of the abstraction spectrum. Most infrastructure details are abstracted away. FaaS platforms provide limited options around the resources and runtime environment provided to compute containers, but control is largely moved from the application developer to the platform.
For example, AWS Lambda provides native Linux-based runtimes for NodeJS, Python, Ruby, Java, Go, and .NET, and enables customization of available RAM up to 3 GB. However, CPU processor and local storage are not configurable.
FaaS is not an ideal choice for developers that require a high level of precision over the configuration of infrastructure and application environment.
As previously mentioned, Function as a Service containers are stateless. While some FaaS providers enable a small amount of temporary local storage during function execution, this local storage does not persist between executions on the same container. In addition, because developers have no insight or control around which container is created in response to a given event, there is no way to directly pass state between specific FaaS containers.
We discuss how Bento approached and resolved this limitation in section 7.1 of this case study.
FaaS providers set a limit on the duration of function execution. AWS Lambda functions have a maximum duration of 15 minutes. Functions that exceed this limit will timeout and return an error.
For this reason, FaaS architecture is not well suited for processes that may take a long time.
FaaS platforms are relatively new, and as a result, tooling around observability is not yet robust. Amazon Web Services provides per-function logging and alerting for AWS Lambda, and similar tools are available across major cloud platforms.
However, FaaS architectures commonly employ several, if not dozens, of different functions that execute concurrently and interact with other backend systems. Related logs and alerts tend to be distributed, rather than centralized. In this complex environment, discovering the existence and cause of errors remains a slow and mostly manual process.
With an understanding of both the strengths and tradeoffs of a FaaS architecture, let’s take a look at how we built Bento.
We built Bento with the primary goal of being fast. Video transcoding running on a single machine is typically a slow process, even with optimizations. Bento aims to offer consumer-grade transcoding speed on low-cost architecture.
The world of video transcoding is deep. There are numerous options and adjustments that can be made to videos during the transcoding process. However, many individuals and businesses tend to have a simple set of requirements around format and resolution. We built Bento to be simple to use. After deployment, uploading and transcoding a video is possible with a few clicks.
Businesses may not want to host their videos on platforms such as YouTube or Facebook for a variety of reasons and may prefer not to host them on a video transcoding platform. Bento is open source software deployed to your AWS account. Videos are uploaded and transcoded to Amazon S3 buckets. Your files remain on your servers.
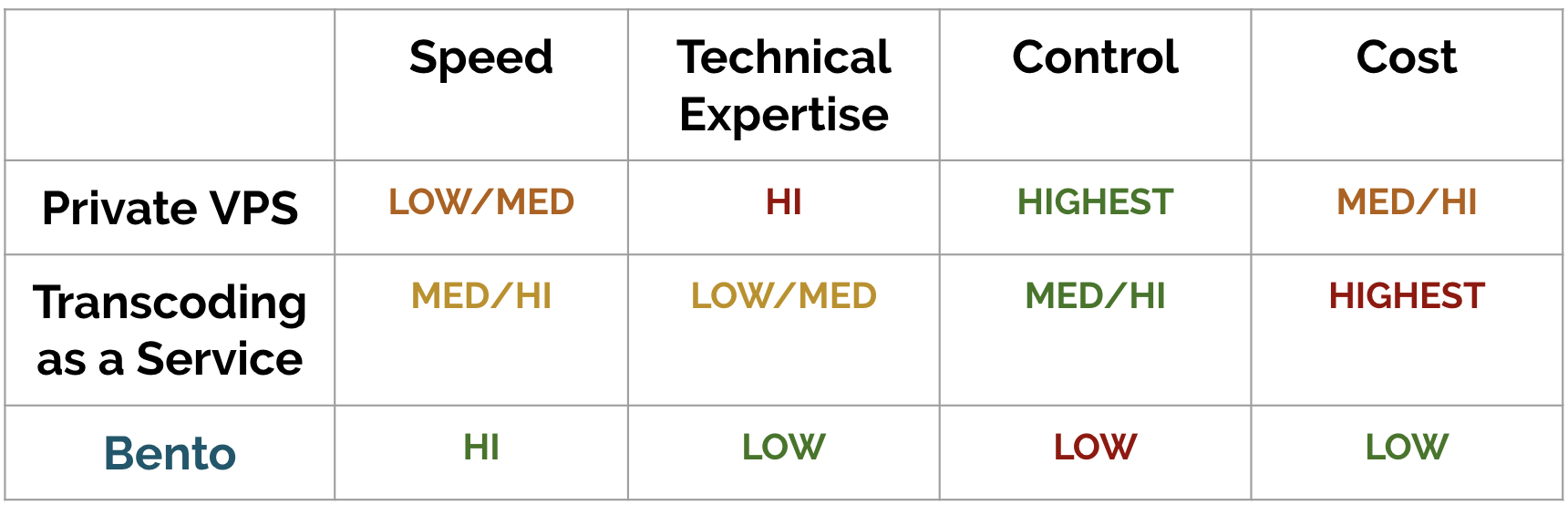
Existing transcoding solutions (in-house transcoding and third party services) provide maximum value for large business. They are ideal for companies that deal with a 24/7 stream of video demands.
However, many small businesses and individuals have video transcoding requirements at a steady, but smaller scale. That could mean processing new videos up to dozens of times a day, or hundreds of times throughout a week, with dead periods in-between. It is for these groups that Bento is best-suited.
Given our use case, we opted to provide less control over transcoding settings along with fewer input and output options. We chose the following inputs and outputs to cover the most common and widely supported video formats and resolutions in use today.
The Bento pipeline currently supports
Because Bento is designed to transcode videos exceptionally fast, we do not pursue compression techniques or video quality optimizations that come at the expense of speed.
The cost of compute/second on a Function as a Service platform is higher than a long-lived virtual server. For businesses with intermittent transcoding demands, this higher cost is offset by not However, video platforms and media businesses that have enough content to spend their full time transcoding would not see a cost advantage with Bento.
However, video platforms and media businesses that have enough content to spend their full time transcoding would not see a cost advantage with Bento.
The FaaS provider that we chose for Bento is AWS Lambda. AWS Lambda is currently the most widely used FaaS platform, and provides the highest limits on configuration details like timeout and memory.
Bento also uses a variety of resources within the AWS ecosystem.
Within our Transcoding Lambdas we are using FFmpeg as our transcoding software. FFmpeg is free, open-source software that can perform a vast number of operations on media files. We use FFmpeg for the transcoding stage and take advantage of a few convenient tools that it provides elsewhere in the pipeline.
Our approach was to send a video file through a pipeline of functions that execute the following steps:
The benefits of employing a FaaS architecture stand out in step two. Let’s take a look into how Function as a Service facilitates this crucial step.
Transcoding a video file creates demand on the CPU and memory of the server doing the processing. Larger files create larger demand on computing resources.
In a traditional computing environment, developers must provision computing resources high enough to meet a predicted maximum load. This provisioning process must maintain a delicate balance: available resources should be high enough that peak capacity is never reached, while ideally not being so high that excess computing capacity goes unused.
Given the extreme variation in the size of video files, effectively provisioning the “right” level of computing power for a single server dedicated to video transcoding is difficult. This is exacerbated for businesses that have intermittent transcoding needs: there may be periods where a server is completely idle, and periods where it is struggling at peak capacity. This is what is referred to as a “bursty” workload. The level of load that hits the system varies greatly over time, and is neither constant nor predictable.
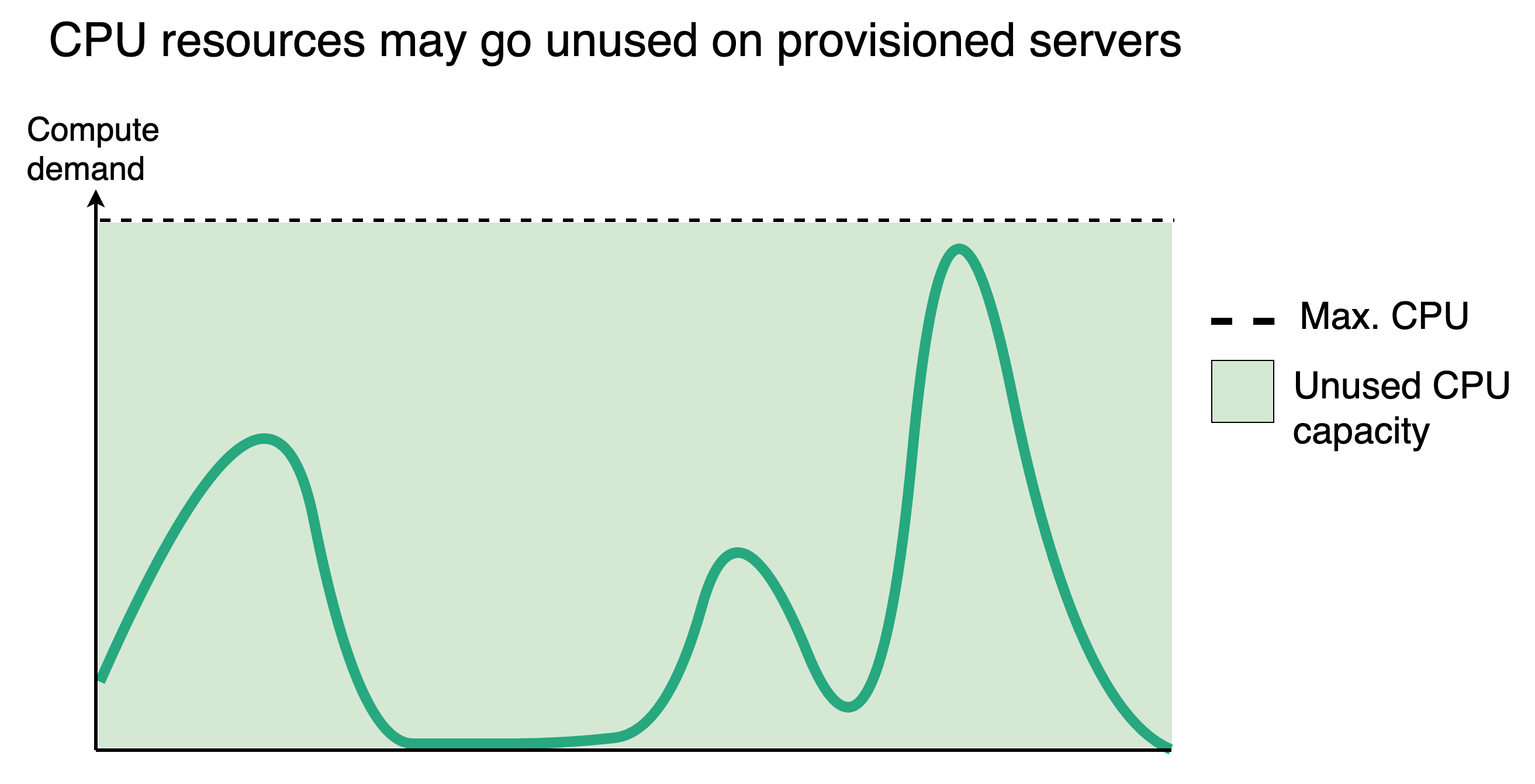
The instant scaling of FaaS is well-suited for bursty workflows as systems can rapidly meet sudden large compute demands and scale back down instantaneously.
For example, when Bento transcodes a video, the file is split into n segments, where n is relative to the length of the video. Bento may produce ten to fifteen segments for a one-minute video, while a sixty-minute video will produce around six hundred segments. Each segment is sent to a transcoding function.
With FaaS, transcoding functions are horizontally scaled to process incoming “segment” events. AWS Lambda supports up to one thousand concurrent executions by default, and containers usually start up within a few seconds. In the context of Bento, this means we can go from a cold start to transcoding up to one thousand video segments simultaneously in under twenty seconds. As transcoding functions complete execution, the system rapidly scales down back to zero as the containers are destroyed.
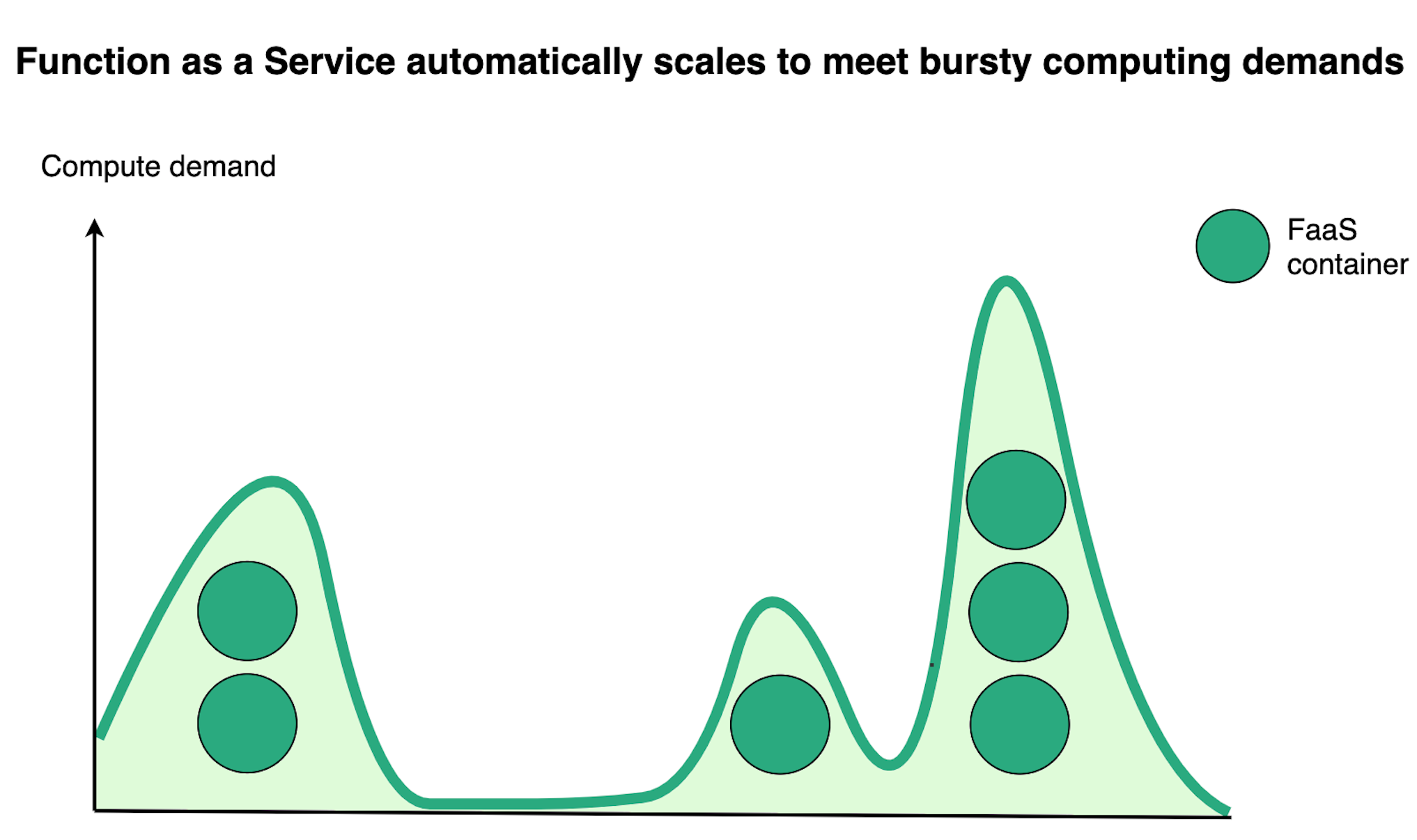
Bento relies on the ability to execute functions concurrently in order to cut total transcoding time.
Video transcoding is serial by default. When a video is transcoded, the file is generally processed from the beginning to the end. Recall that video files are very large and the transcoding process is very slow.
As an example, let’s imagine transcoding a large video file from beginning to end. Transcoding the first quarter of the video might take roughly thirty minutes, the next quarter would take around the same amount of time, and so on. The entire transcoding job for this single video, handled in a linear fashion, would take about two hours.
Bento divides a single transcoding job into parts that are processed in parallel. In the previous example, imagine that we split the video file into quarters. If we transcode them all at once, that would mean: four segments, thirty minutes for each segment, transcoded in parallel. Transcoding this way would bring our two-hour job down to just thirty minutes.
We’ve cut the total transcoding time by 75% in this example scenario. However, Bento’s implementation doesn’t divide videos into quarters. In our approach, we decided to split video files into segments that are between two and six seconds in duration. This results in dozens, sometimes hundreds, of small segments that usually take under a minute to transcode.
Bento leverages the high concurrency of Function as a Service architecture to transcode these segments in parallel. The result is a significantly shorter time spent transcoding.
We benchmarked Bento against two options that individuals and small businesses might choose for video transcoding.

The first alternative is a free-tier EC2 instance with 1 GB of RAM, running FFmpeg. While this is a barebones option for professionals, it represents a clear baseline to benchmark Bento’s performance against traditional, non-optimized video encoding on a single machine.
For the second alternative, we chose Amazon Elemental MediaConvert. MediaConvert is a feature-rich transcoding service, aimed at professional broadcasters and media companies. While Bento does not provide the same set of transcoding options, we wanted to demonstrate the speed Bento can achieve against professional-grade software.
As a test, we measured the time it took Bento and these two alternatives to output a video file to MP4 format at 1280x720 resolution.
We benchmarked against nineteen test videos, whose size ranged from four megabytes to two gigabytes, and whose duration spanned seven seconds to ninety minutes.
In the chart below, we provide a cross-section of benchmark data that illustrates the results we saw at small (< 100MB), medium (100+ MB), large (1+ GB) and very large (2+ GB) file sizes.
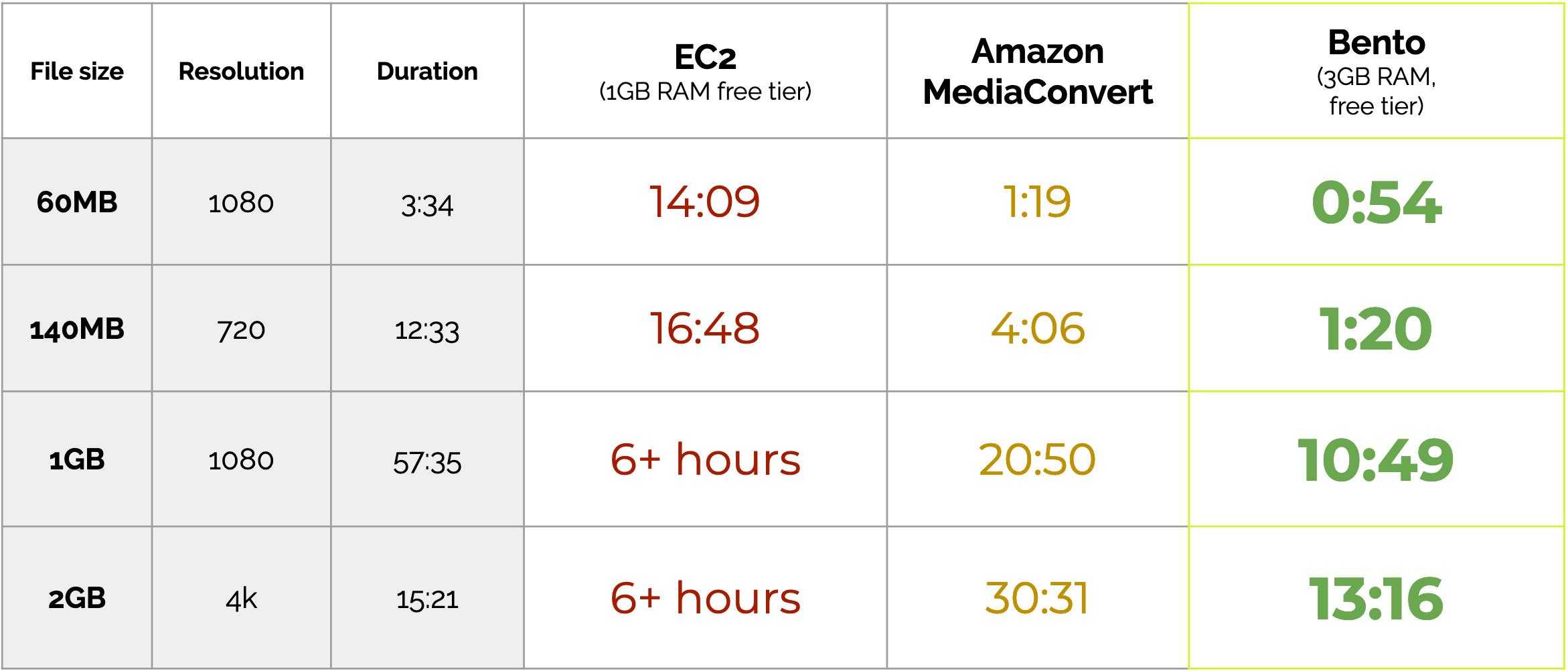
Our benchmarks demonstrate that a serverless, massively parallel approach to video encoding results in significant improvements to transcoding speed.
Bento consistently performs over 90% faster than an EC2 instance in our benchmarks, and 50% faster than Amazon’s MediaConvert transcoding service across a variety of file sizes, video durations, and format types.
Let’s dive into Bento’s architecture and explore how Bento achieves these results.
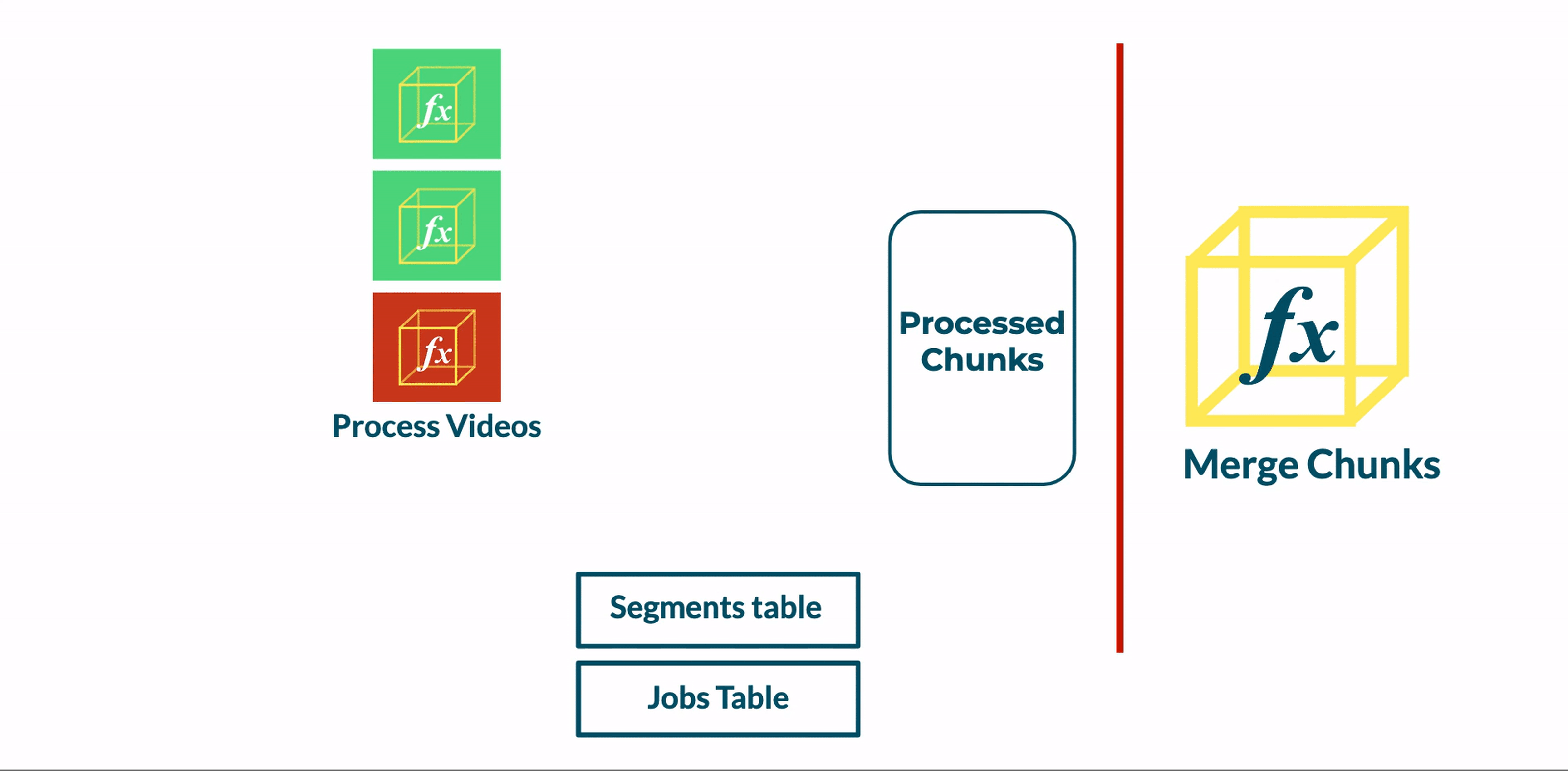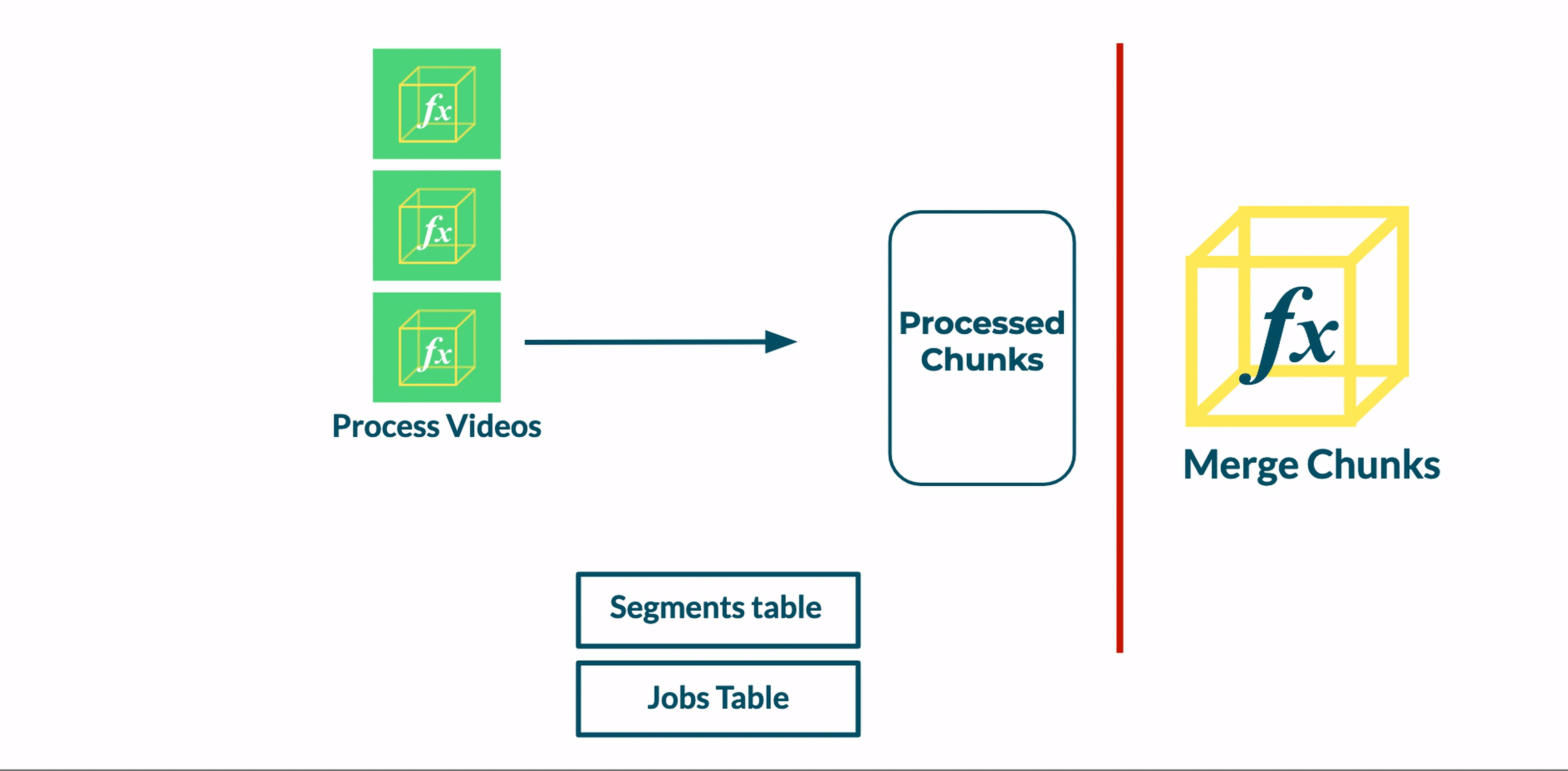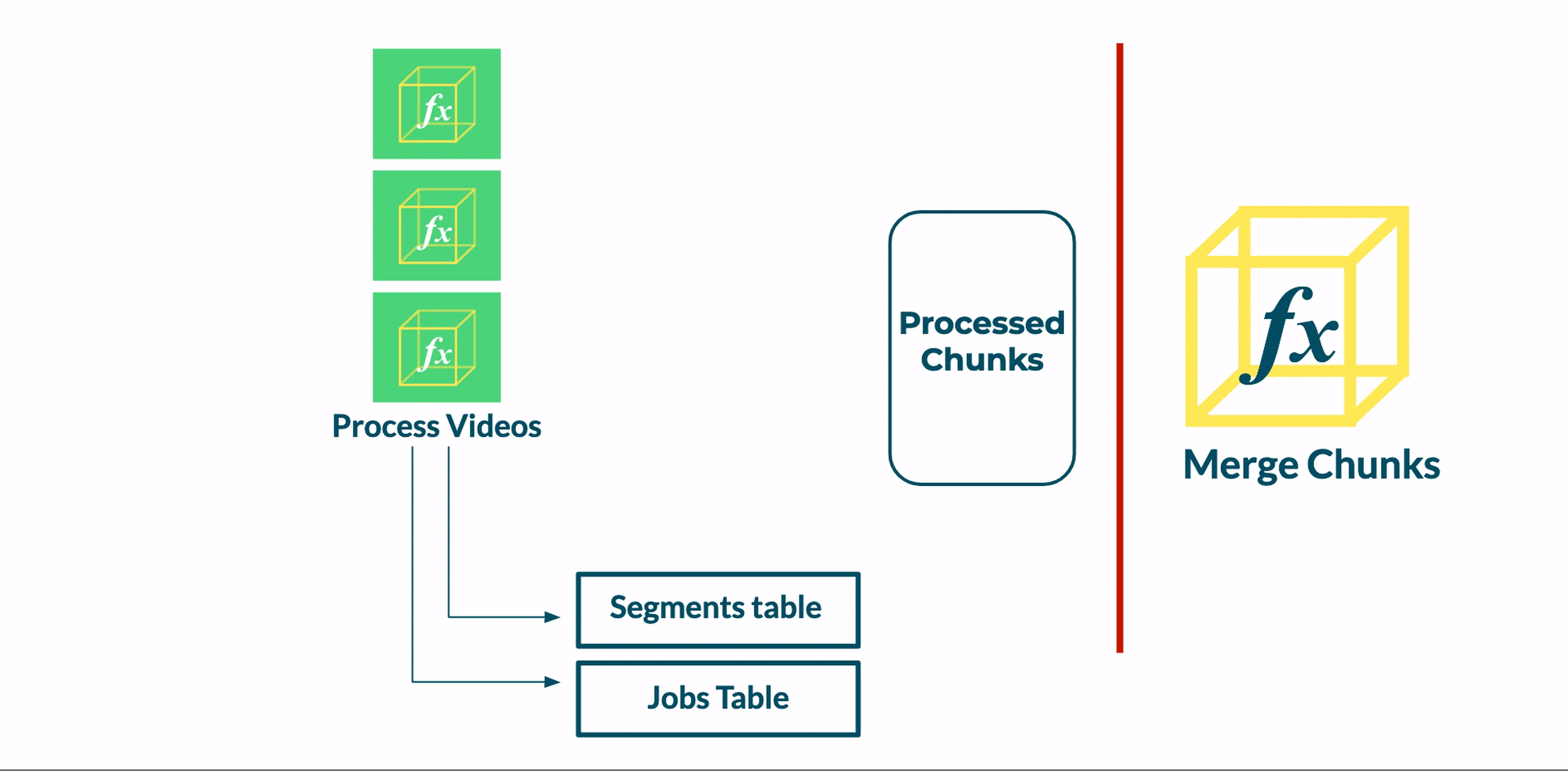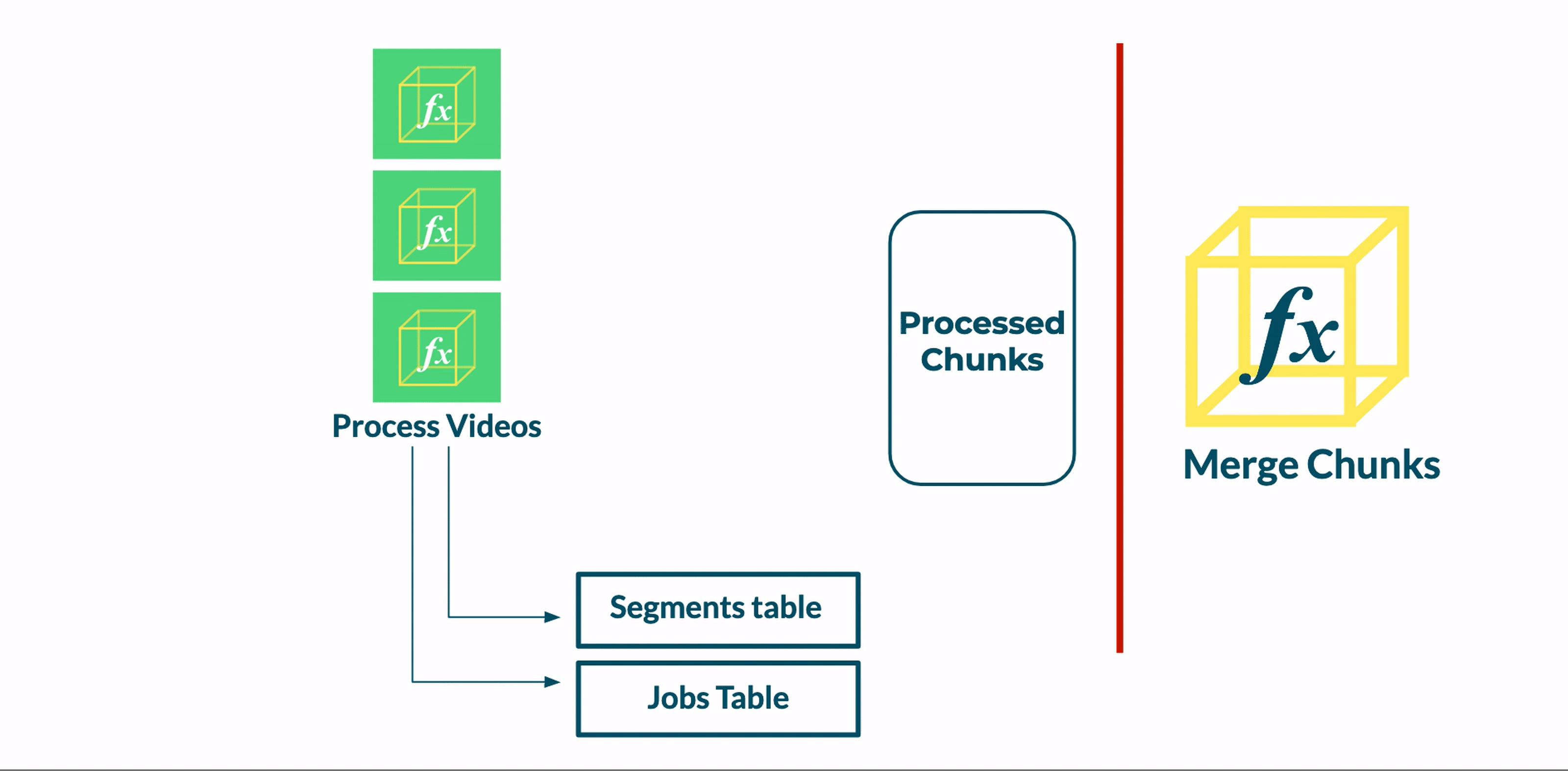
The Bento pipeline consists of four stages, organized in a fan-out fan-in pattern. In a fan-out fan-in pattern, a single large task is split into multiple smaller subtasks that are run in parallel (fan-out). The results of those individual subtasks are then aggregated and processed by a single reducing function (fan-in).
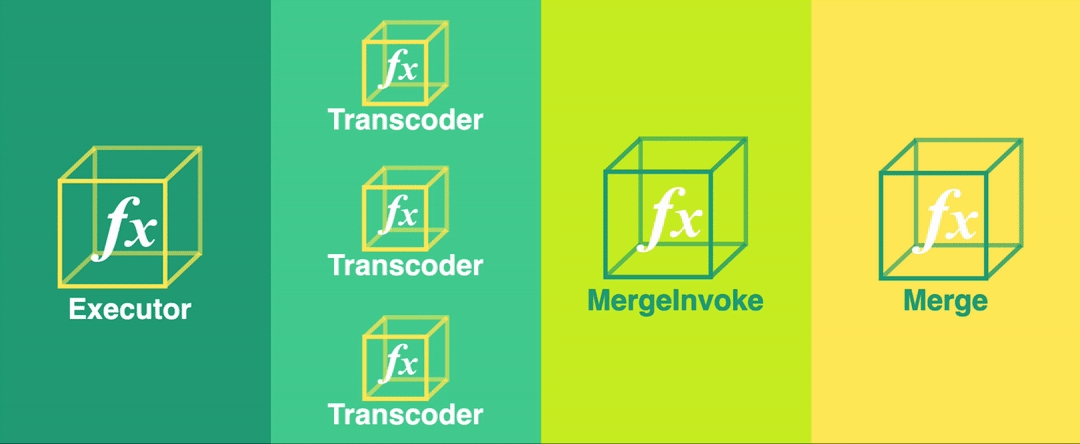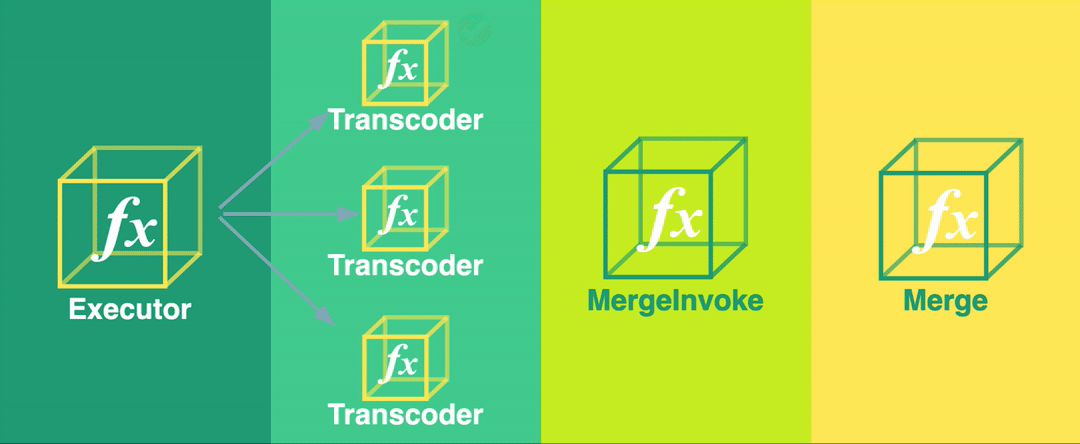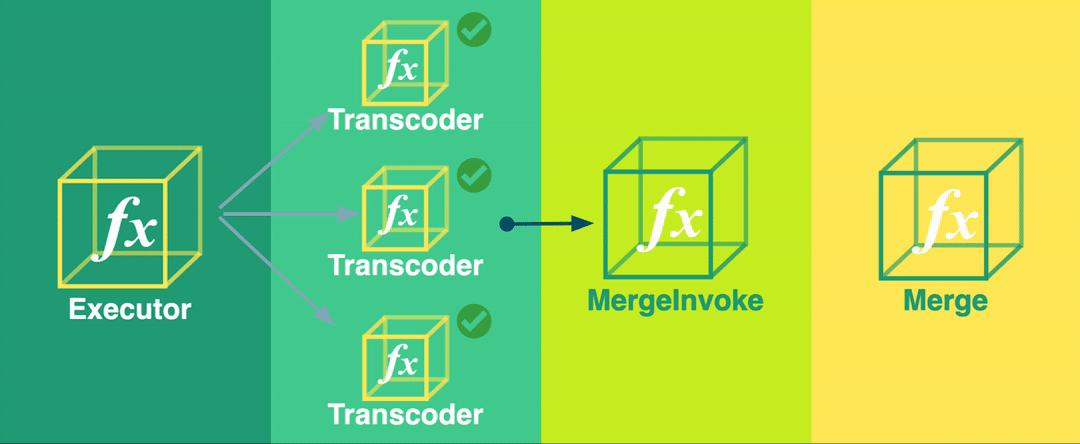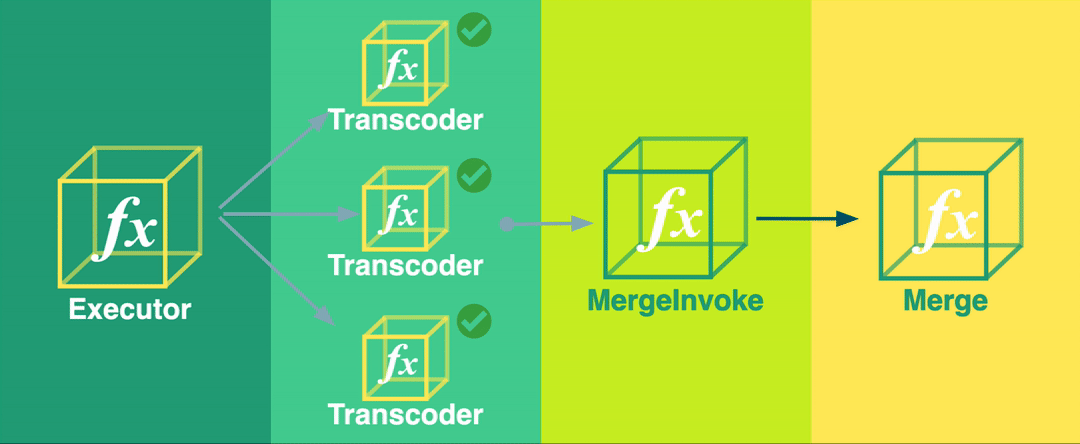
Bento’s four stages are:
The Executor function determines the start and end times of each video segment and invokes an instance of the Transcoder function for each one of these segments.
The Transcoder function transcodes a small segment of the video file and saves the segment to intermediate S3 storage. Multiple instances of the Transcoder function run at this stage - one for each segment.
The Merge Invoker function checks the state of the pipeline to determine when all segments have been transcoded. At that point, it invokes the Merge function.
The Merge function concatenates the transcoded video segments into a complete, transcoded video.
Let’s explore how we built each stage in more depth.

To begin the process, the Executor receives an invocation event triggered by Bento’s admin dashboard. The body of the request has information about which video to transcode and what the resolution of the transcoded video should be.
Our first concern is splitting an original video file into segments that can be passed to instances of a transcoder function.
Our initial approach was to use Ffmpeg’s segment muxer. This tool divides an input video into segments of m-second length. As a starting point, we chose segments that were four seconds in length.
At this point, we invoke the Transcoder function for each video segment. We save each video segment to S3, and then pass the location of a video segment in S3 to each invocation of the transcoder function.
Although this approach achieves our objective, we noticed early on that the Executor function was taking much longer than we expected to complete. Video files that were a few hundred megabytes were hitting our function’s execution time limit of fifteen minutes.
As it turns out, Ffmpeg’s segment muxer was transcoding the entire video file as it was splitting it into segments. At this point, we were encountering the exact challenge that Bento aims to solve - slow video transcoding on single machines.
We decided on an alternate approach. Rather than splitting a video file into segments, we use the Executor to map out the start and end times of each segment we want to create.
We can then have each instance of the Transcoder function work with the full video file, but only transcode within the bounds of the times that we pass to it.
Within the Executor, we use another FFmpeg utility, Ffprobe, to examine the video and collect metadata about the video’s keyframes and timestamps. The Executor function uses this information to determine the start and end times of each segment.
We save information about each segment to a table in DynamoDB, and save the status of the entire transcoding job to a separate table. In section 7.1 of this case study, we will explore the challenges of preserving state across Function as a Service in more detail.
Once the Executor maps out segment data, it finishes by invoking an instance of the Transcoder function for each segment. It passes along the desired transcoding settings, and the start and end times that the instance is responsible for processing.
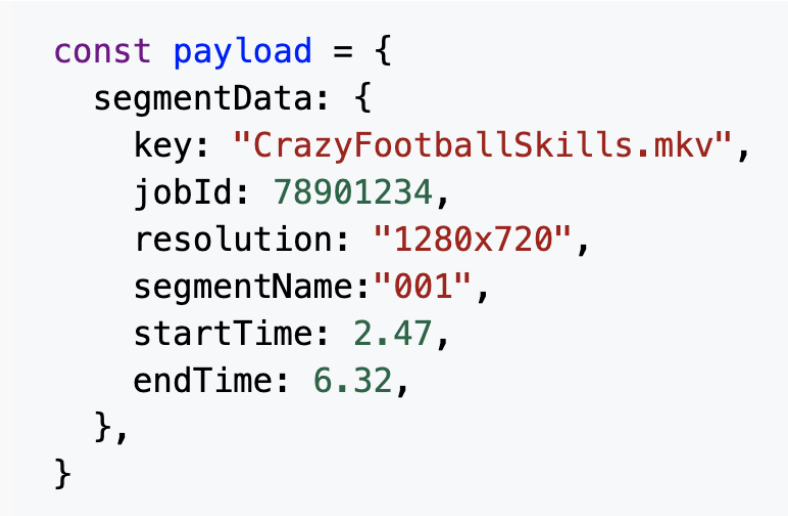
The Executor invokes an instance of the Transcoder, passing along the start and end times of the segment to produce

The Transcoder function receives information about the transcoding job, including the timestamps that mark the beginning and end of a segment in the original video.
Because AWS Lambda functions have limited temporary local storage, we quickly realized that we needed to transcode the original video file without saving it to disk. Fortunately, FFmpeg accepts input over HTTP, allowing us to process the video in memory and bypass the need to store the full file locally. We expand on the challenges of storing and processing large video files in a FaaS architecture in section 7.2 of this case study.
To transcode a segment of the video, we pass the URL of the original video file to FFmpeg, along with the desired transcoding settings, and the start and end times of the segment. FFmpeg uses the h264 codec to transcode the video segment and packages it in the MP4 container.
The result of this transformation, an m-second video in MP4 format, is saved to temporary local storage. The function uploads this newly created segment to an intermediate S3 bucket for persistent storage.
After uploading the segment to S3, the Transcoder updates the records for the segment and job in their respective DynamoDB tables, marking an additional segment as completed.
Before we move on, it's important to note that although we are zoomed in to look at a single instance of the Transcoder function, there may be hundreds of Transcoder functions executing in parallel, each working on a different segment of the original video.
As each instance of the Transcoder function finishes transcoding its respective segment, we need to carefully consider how - and crucially, when - to concatenate the segments into a complete transcoded video.
Goals:

When we first outlined our approach to building Bento’s transcoding pipeline, as we did in section 4.4, we described a three-step process: split, transcode in parallel, then merge.
However, we reach the end of the Transcoder stage, we require some sort of event to indicate that we are ready to move to the Merge stage. Generating this event becomes a significant challenge, as the stateless nature of FaaS containers and the unpredictable timing of concurrently executing functions prevents a straightforward approach to coordinating the final step. These challenges are explored in detail in section 7.1.
The Merge Invocation stage encapsulates the solution to this problem. The objective of this stage is to invoke the Merge function only when all the segments of a video have been successfully transcoded.
To implement the Merge Invocation stage, we rely on a feature of DynamoDB, called DynamoDB Streams. DynamoDB Streams are time-ordered series of records that are created when a given database table is updated. Each record encapsulates a change that was made to an item in the table. Crucially, Lambda functions can be triggered when new records are added to the stream. This behavior forms the basis of the Merge Invoker.
First, we attach a DynamoDB Stream belonging to the Jobs table to the Merge Invoker function.
A record in the Jobs table maintains a count of the total number of segments to be transcoded for that job, and the number of completed segments that have been successfully transcoded. When a segment has been transcoded, the Transcoder function updates the associated job record, incrementing the number of completed segments by one.
The update causes the Jobs table to emit a record into the event stream, which in turn invokes the Merge Invoker function.
The Merge Invoker receives the event from the stream, which contains the latest snapshot of the job record. The function compares the number of completed segments to the total number of segments to determine whether all the segments for this particular job have been successfully transcoded.
If all the segments are transcoded, the Merge Invoker will invoke the Merge function.
When the Merge function is invoked, all transcoded segments are available in intermediate S3 storage to be merged into the final file. To merge these videos together, we use the ffconcat utility provided by FFmpeg, which concatenates multiple input files into a single output file.

As in previous stages, our intention was to perform this processing without saving the video segments, or the complete final video, to temporary local storage. As before, we employed Ffmpeg’s ability to process input via HTTP to concatenate the video segments in memory.
To avoid storing the final file on disk, we piped Ffmpeg’s byte stream output directly to S3 storage. We expand on the challenges of streaming this video data directly to remote storage in section 7.2
Once the completed video file has been saved to S3, we update our record in the Jobs table to indicate that the transcoding job has been completed. With that, the job is complete.
We faced two main problem domains while building Bento: 1) dealing with concurrency in the context of Event Driven Architecture and 2) limited function storage.
FaaS functions are event-driven. Therefore, building an application with Function as a Service implies the use of an Event Driven Architecture.
In section 6 of this case study, we refer to specific Lambda functions being “invoked” by other functions. This is a reasonable, but incomplete mental model for the interaction that takes place.
When a function in the Bento pipeline is “invoked”, it is responding to an invocation event that is placed in a messaging queue. Invocation messages can be placed in a Lambda function’s queue as a response to an AWS API request - for instance, when the Executor “invokes” the Transcoder function. Invocation messages can also be added in response to changes in state in other backend systems - for instance, a record emitted by DynamoDB Stream is enqueued by the Merge Invoker function. Lambda functions spin up to consume all the available messages placed in their queue until there are no more messages remaining in the queue, or a concurrency limit is reached.
Event Driven Architecture stands in contrast to more tightly coupled procedural programming patterns like REST. Interactions occur asynchronously, and event producers are decoupled from event consumers. One of the features this facilitates is the rapid scaling FaaS is able to accomplish in response to incoming events.
Purely event-driven applications react to internal and external events without a central orchestrator. Instead, execution flow is completely determined by the occurrence of individual events.
However, Bento requires that functions are executed in a specific order to ensure the success of a transcoding job. For instance, the timing of the Merge stage is critical. The Merge function can only assemble transcoded segments into a final video when all of the segments are available.
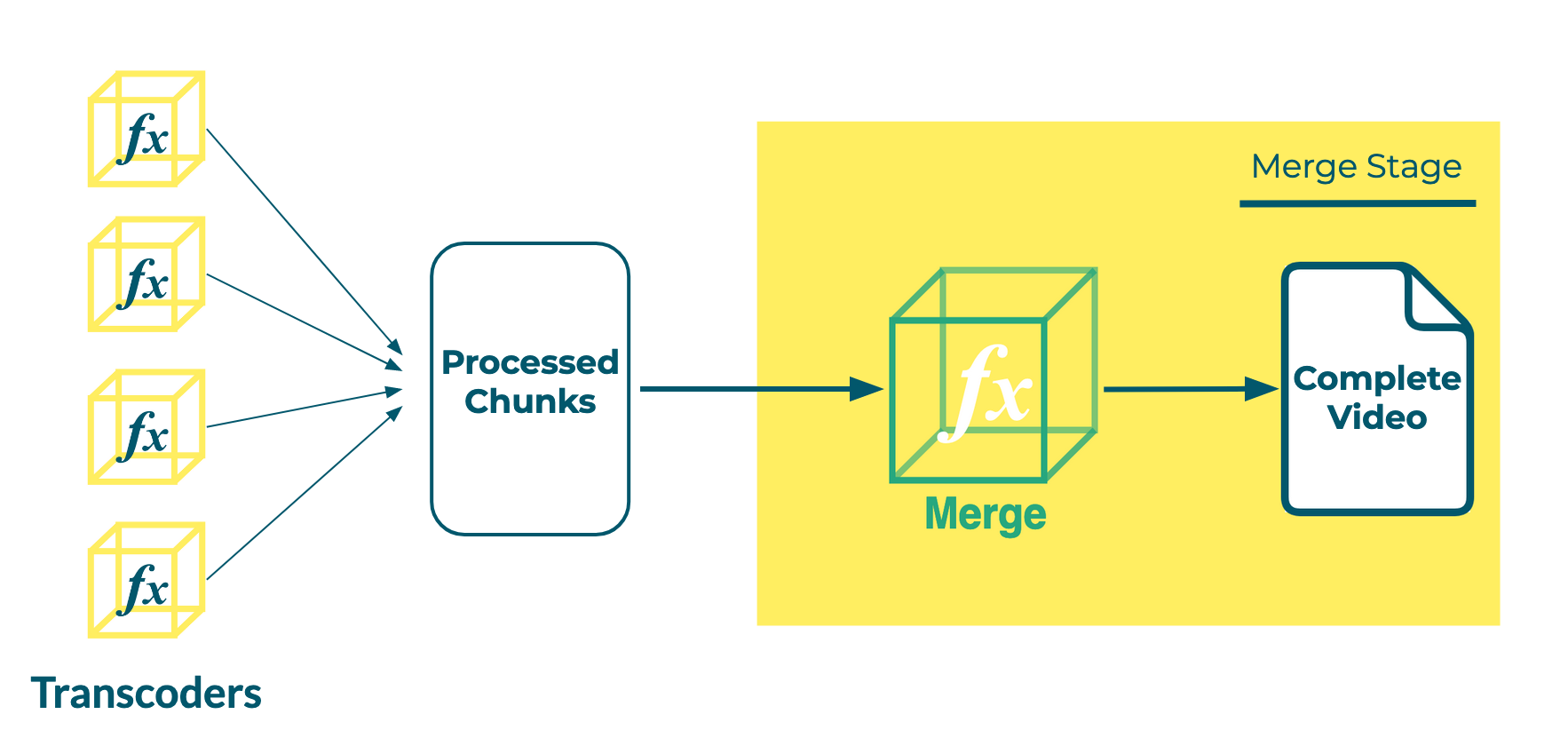
Because of this timing concern, we required a reliable event to trigger the Merge stage. Without a central orchestrator to monitor the multiple concurrent instances of our Transcoder function, we considered whether the event could be produced by a specific instance of a Transcode function. For example, if we could predict which function instance would be the last to complete, we could use that instance to “invoke” our Merge function.
However, this is prevented by the unpredictable timing of concurrently executing Transcoder functions. Although earlier executions of the Transcode function are likely to complete before later invocations, we found that the order of completion varied significantly.
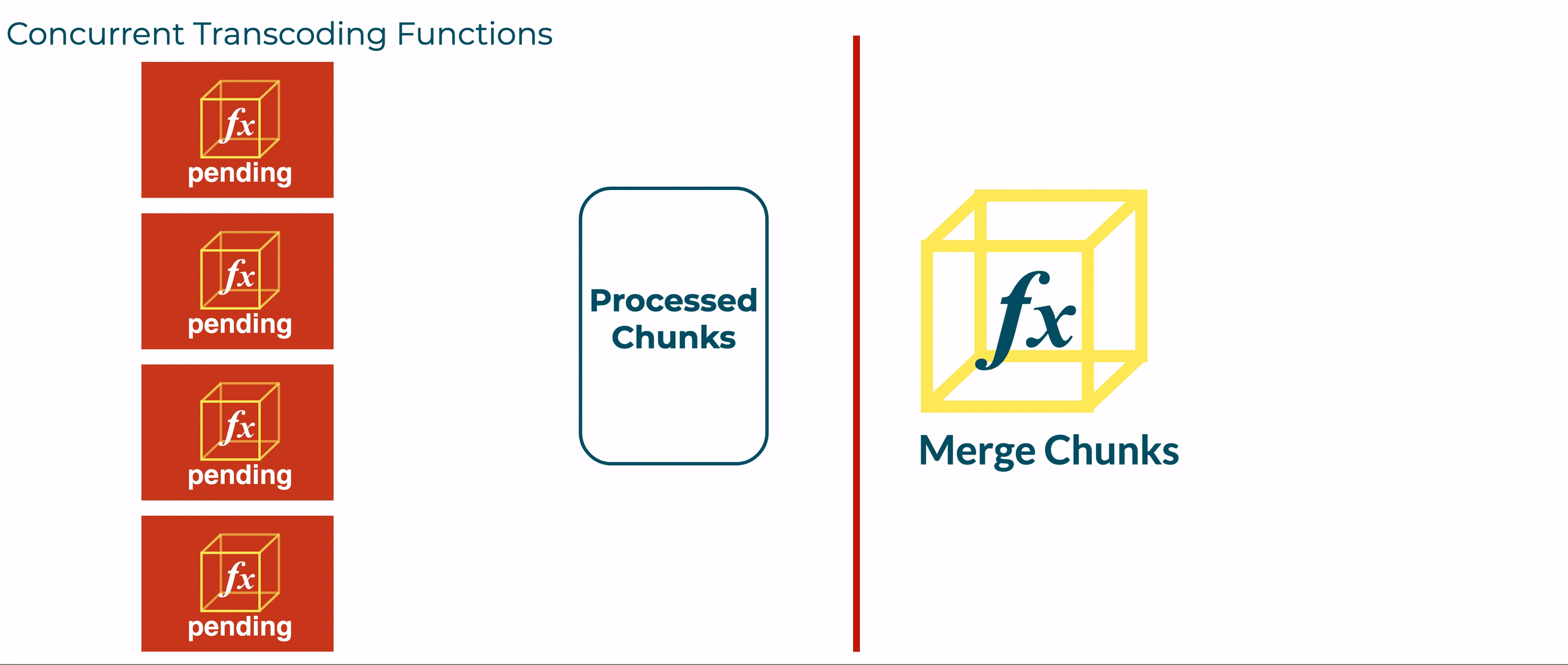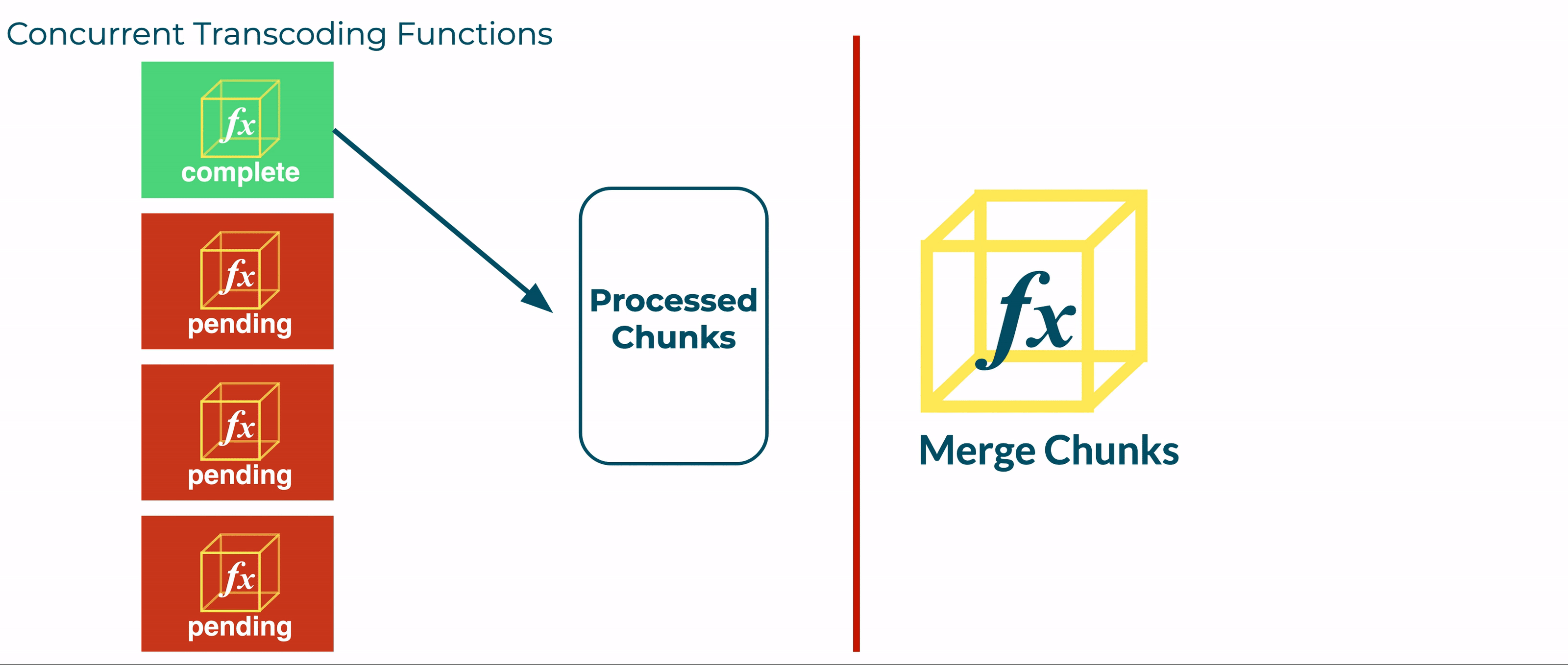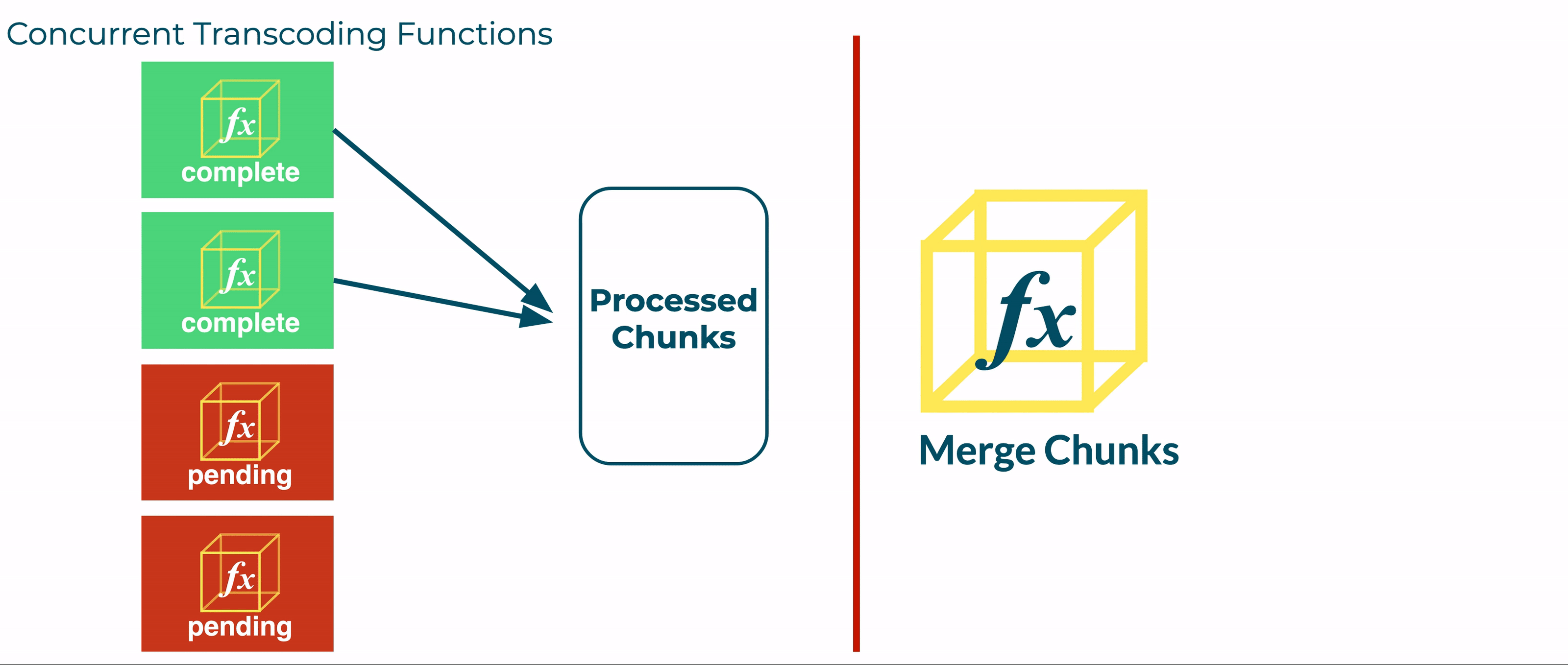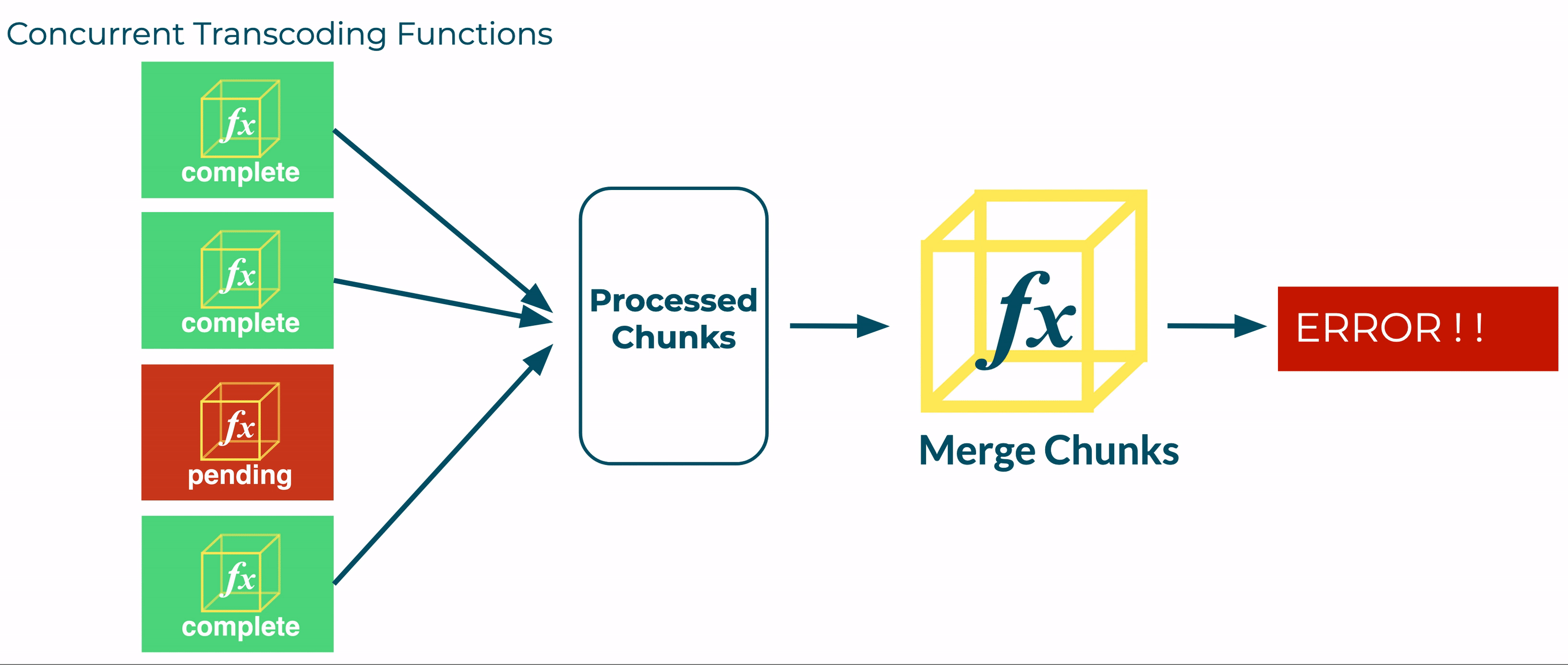
If the fourth Transcoder was predicted to finish last, the merge function would have been invoked prematurely, before all the segments were available.
Since we can not predict which Transcoder instance will be the last to complete, we considered introducing a source of persistent state to our pipeline’s design.
Functions could refer to this stateful resource throughout the pipeline to gain access to the overall status of a transcoding job and make state-driven decisions. We decided to use DynamoDB tables to capture job metadata, such as how many of the segments of a video have been transcoded.
By introducing a database to our pipeline, we discovered that concurrent processes interacting with a database can quickly lead to race conditions.
Following the addition of a database, we updated our Transcoder function to save metadata about the status of its given video segment. After transcoding a segment, the Transcoder function a) updates a segment’s status from pending to complete in the Segments table and b) increments a count of completed segments in the Jobs table.
At this point, the database reliably reflects the state of the job. However, it cannot directly orchestrate the transition from the transcoding stage to the merging stage.
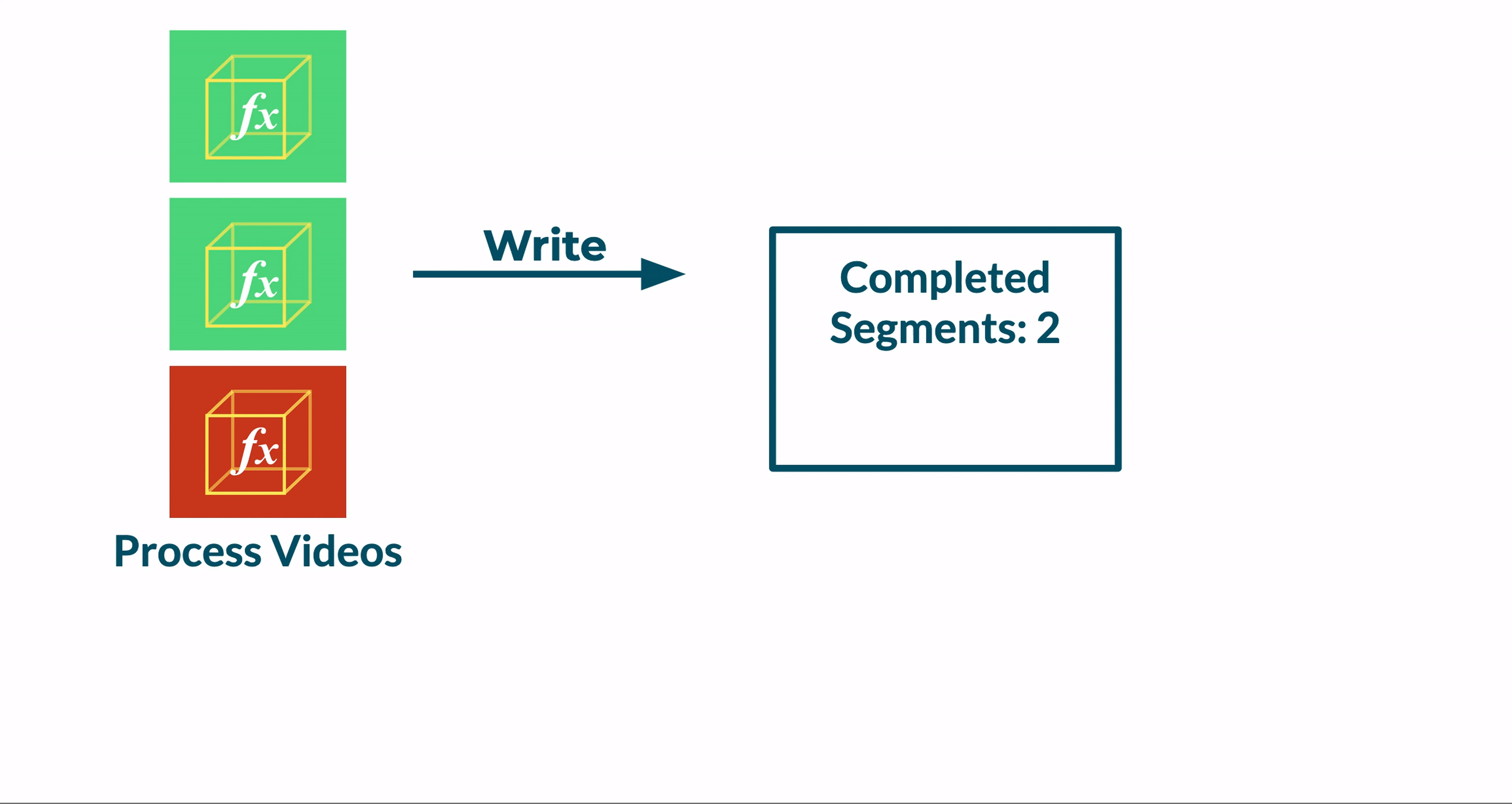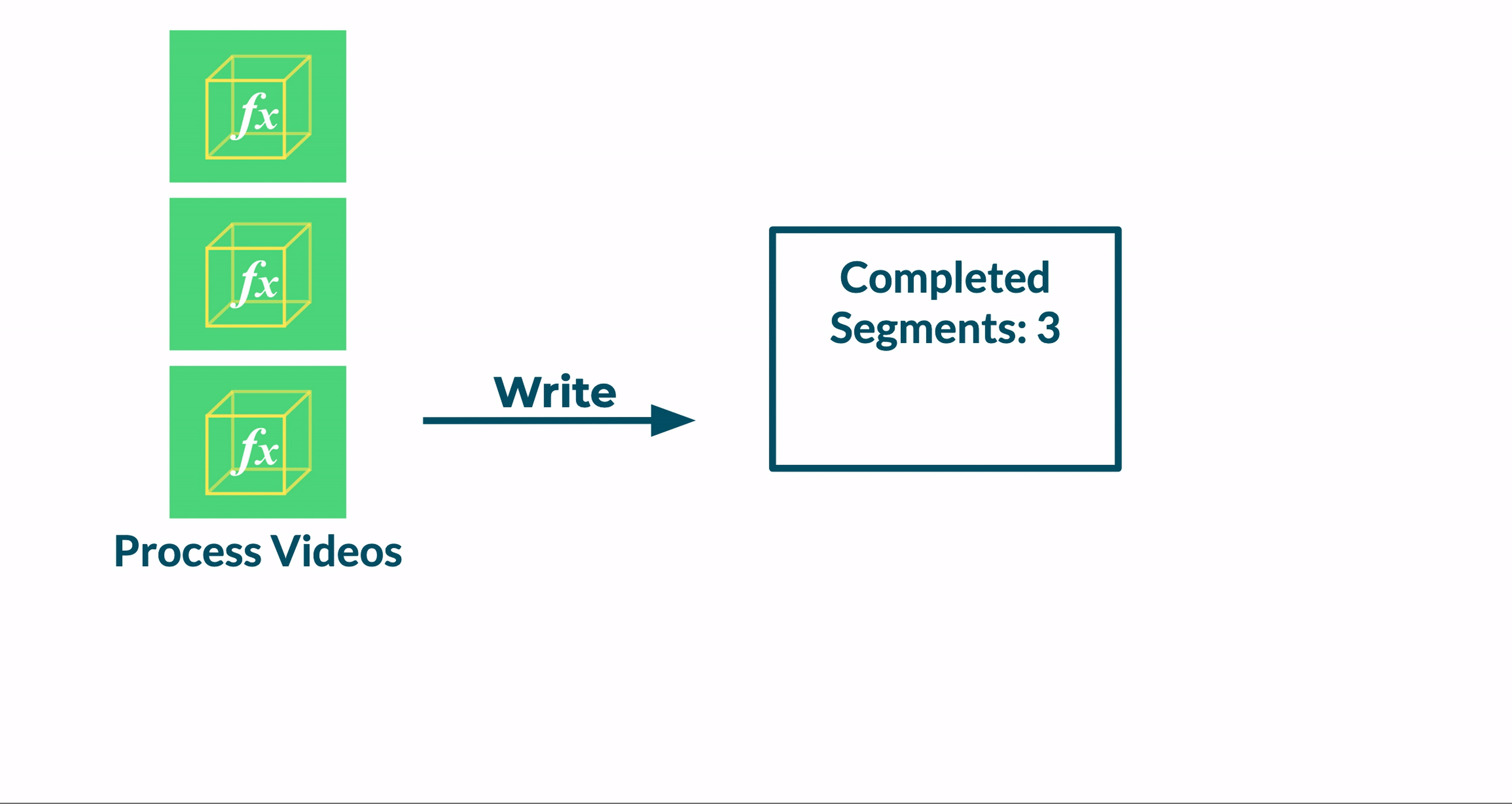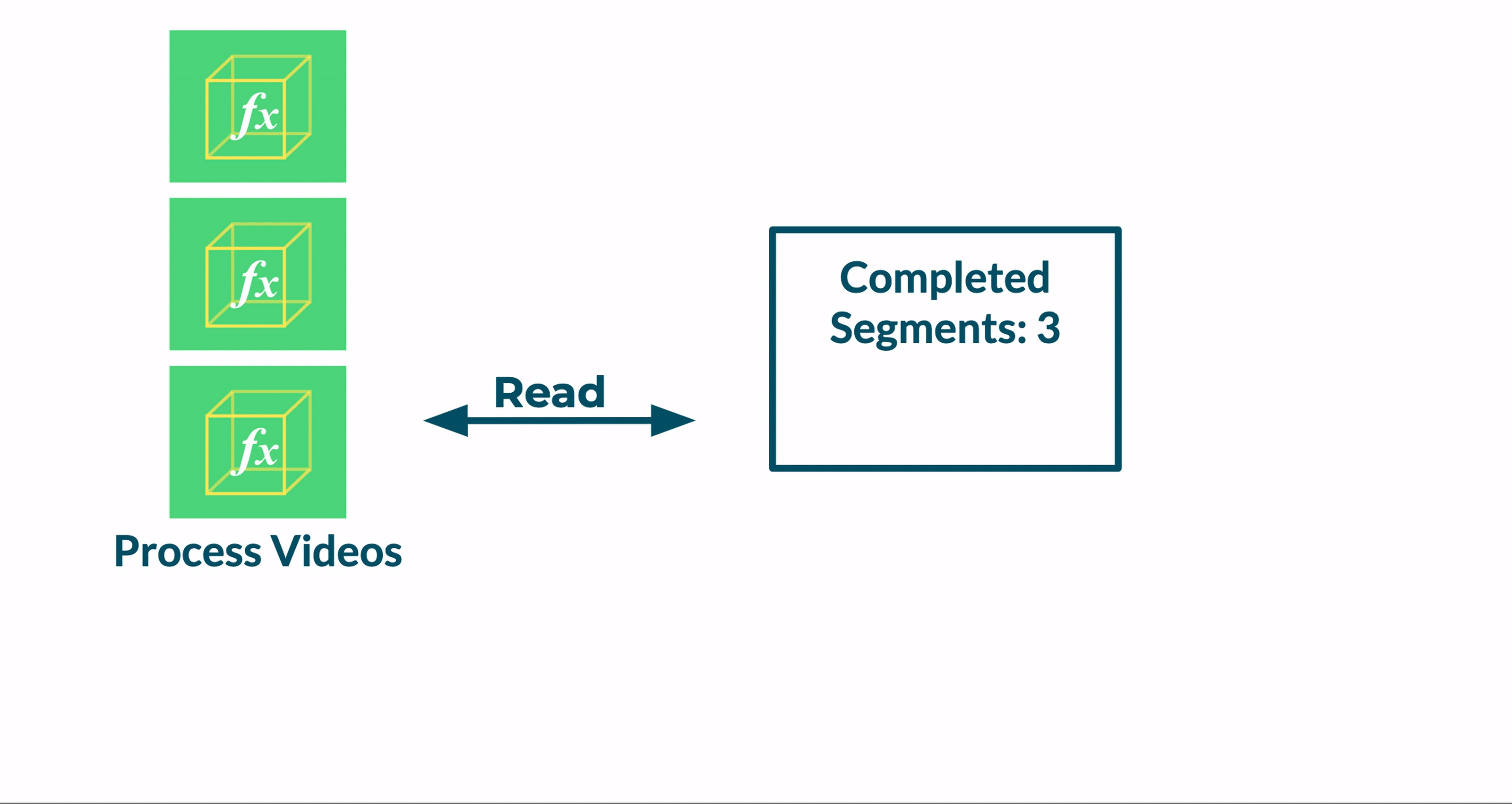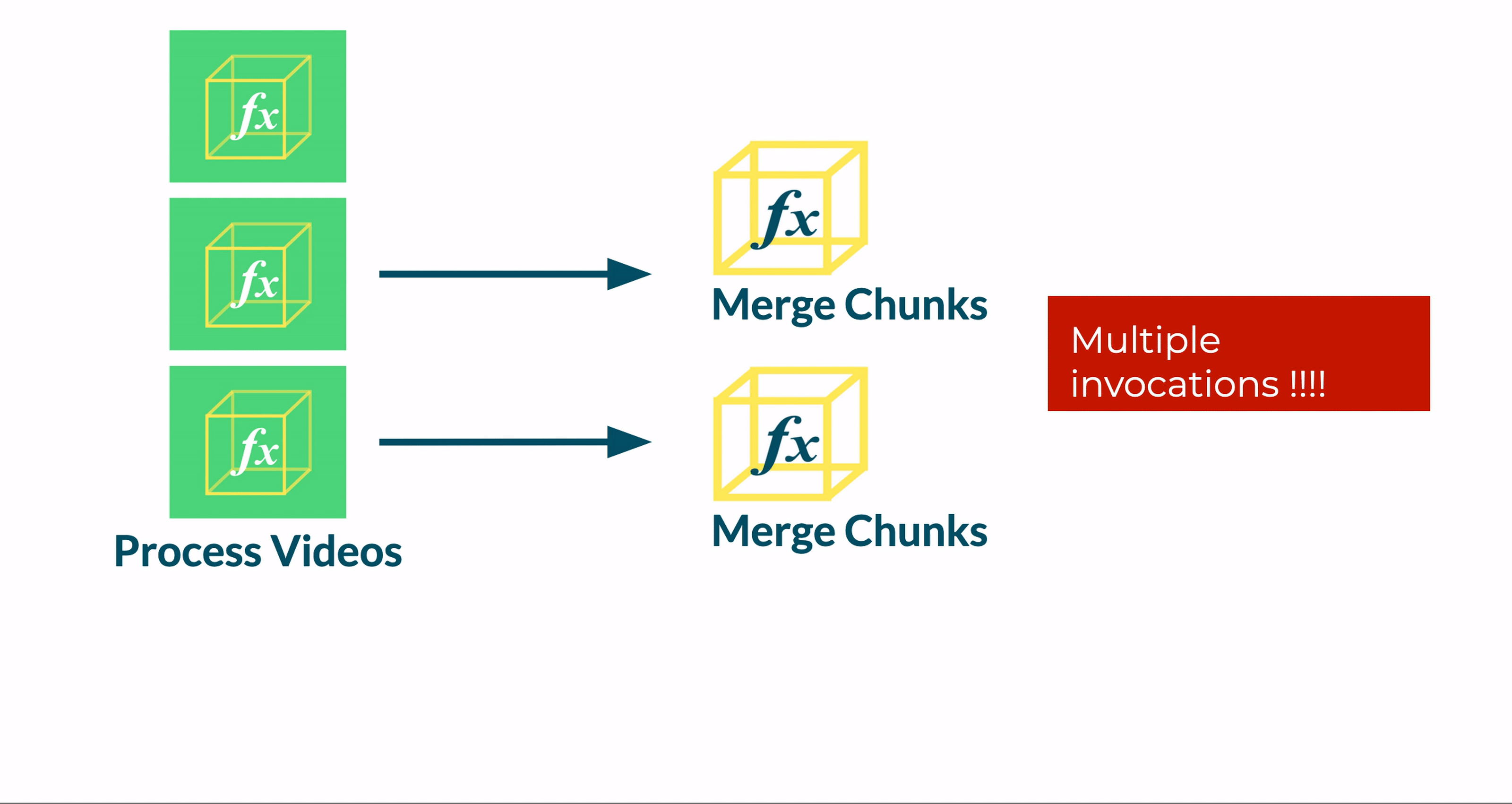
We tested a new approach, where any Transcoder instance could invoke the Merge function. Before winding down, each function instance would a) read the Jobs table, b) check if all the segments for a job were transcoded and c) trigger the merge phase if all the segments were ready. We found that this approach was not reliable because a race condition was introduced.
This race condition stems from a window in time after a Transcoder function updates the Jobs table to indicate that the final segment is complete. During this window, other instances of the Transcoder function may read from the Jobs table, see that all segments are complete, and invoke the Merge function. As a result, the Merge function will be invoked multiple times.
Change data capture refers to a process of identifying and capturing changes made to a database. The process has a wide variety of use cases, from syncing database replicas to driving push notifications.
In the context of Bento, we decided to use change data capture to monitor the state of a job in the Jobs table in real-time as Transcoder functions write updates to its record. In essence, the change data capture pattern provides serialized and reliably time-ordered reads of changes to the Jobs table that occur concurrently and unpredictably.
Change data capture is enabled by DynamoDB Stream, a feature of DynamoDB. Each update to an item in the database is recorded and inserted into an event stream that can be consumed by other resources. The stream record provides a snapshot of the values of the updated item within the database.
To implement the change data capture pattern, we enable a stream on the Jobs table. Every time we increment the completed segments counter on a job record, we will now produce a stream record that includes the count of completed segments and the total number of segments to transcode for that job.
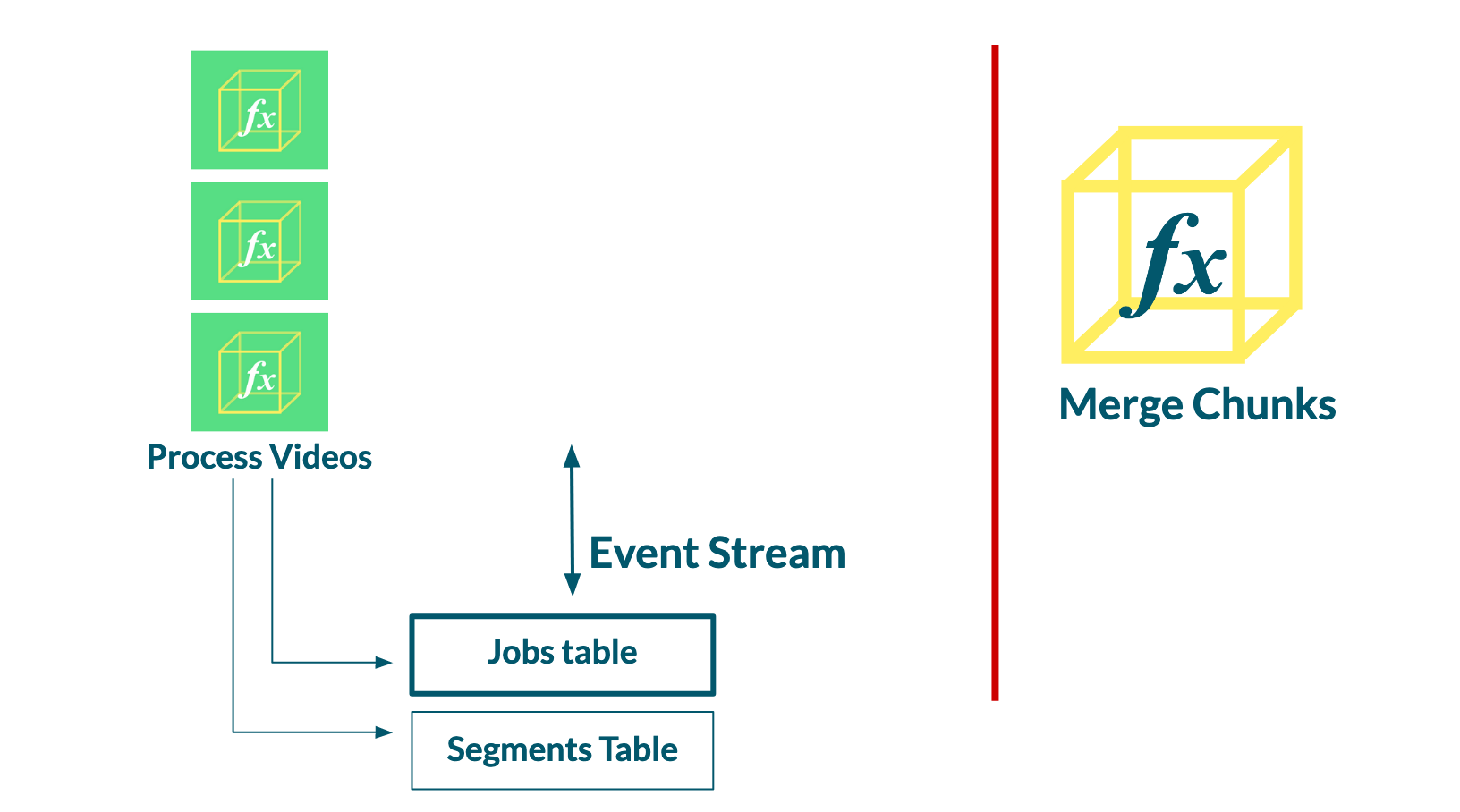
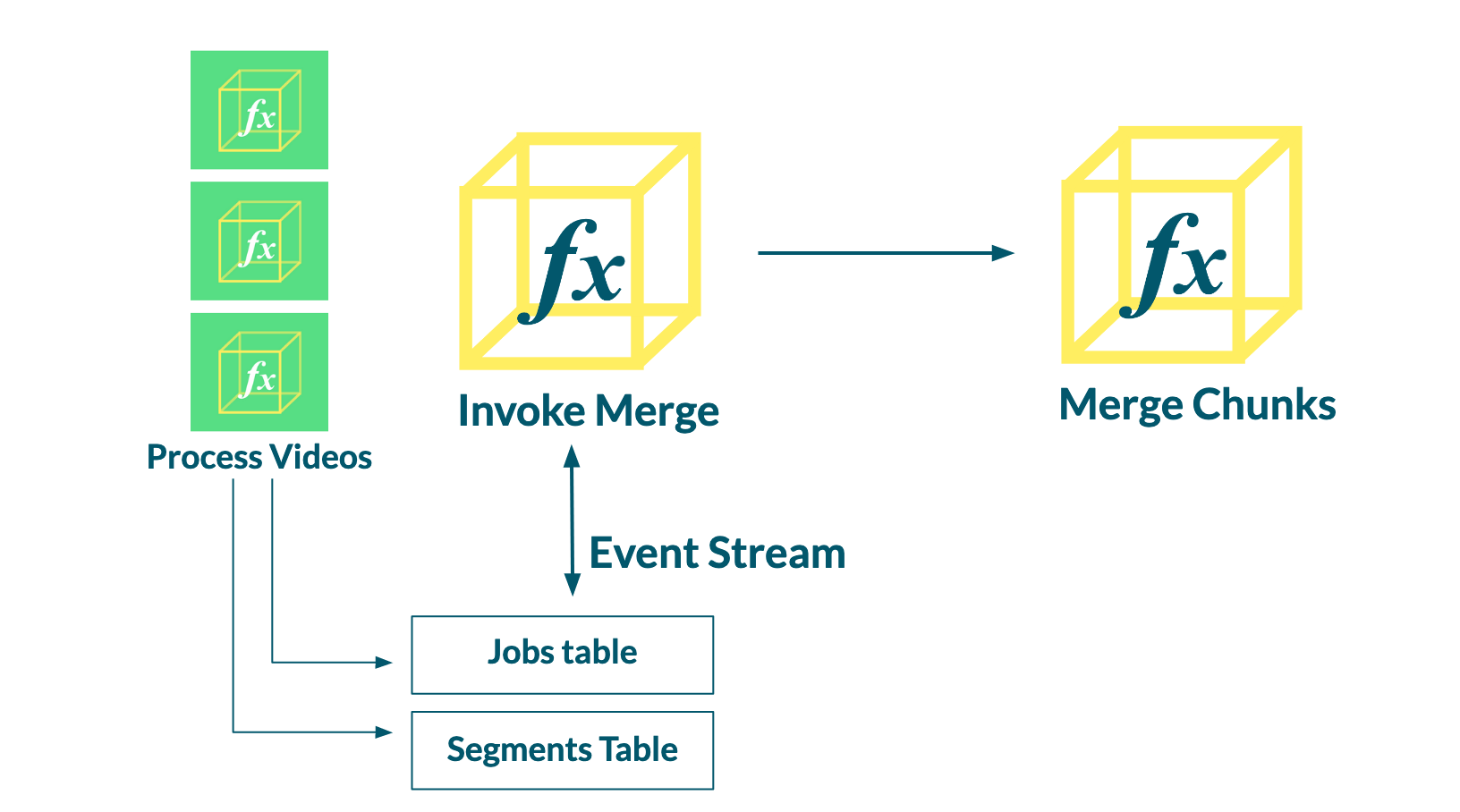
A resource is now required to examine the records in this stream. We decided to create the Merge Invoker function and task it with the sole responsibility of consuming stream records from the Jobs table to determine when to invoke the Merge function.
We then attach the Merge Invoker to the Jobs stream so that the function is invoked when new stream records are detected. The Merge Invoker receives each record as an argument. When the number of segments completed reaches the total number of segments for the job, Merge Invoker invokes the Merge function.
While pursuing an event-driven architecture in Bento, we encountered common problems related to concurrency: it is difficult to track the state of concurrently running processes, and race conditions are common. Adding a database operating under a change data capture pattern resolves these issues and provides us with tighter management of the pipeline’s flow of execution.
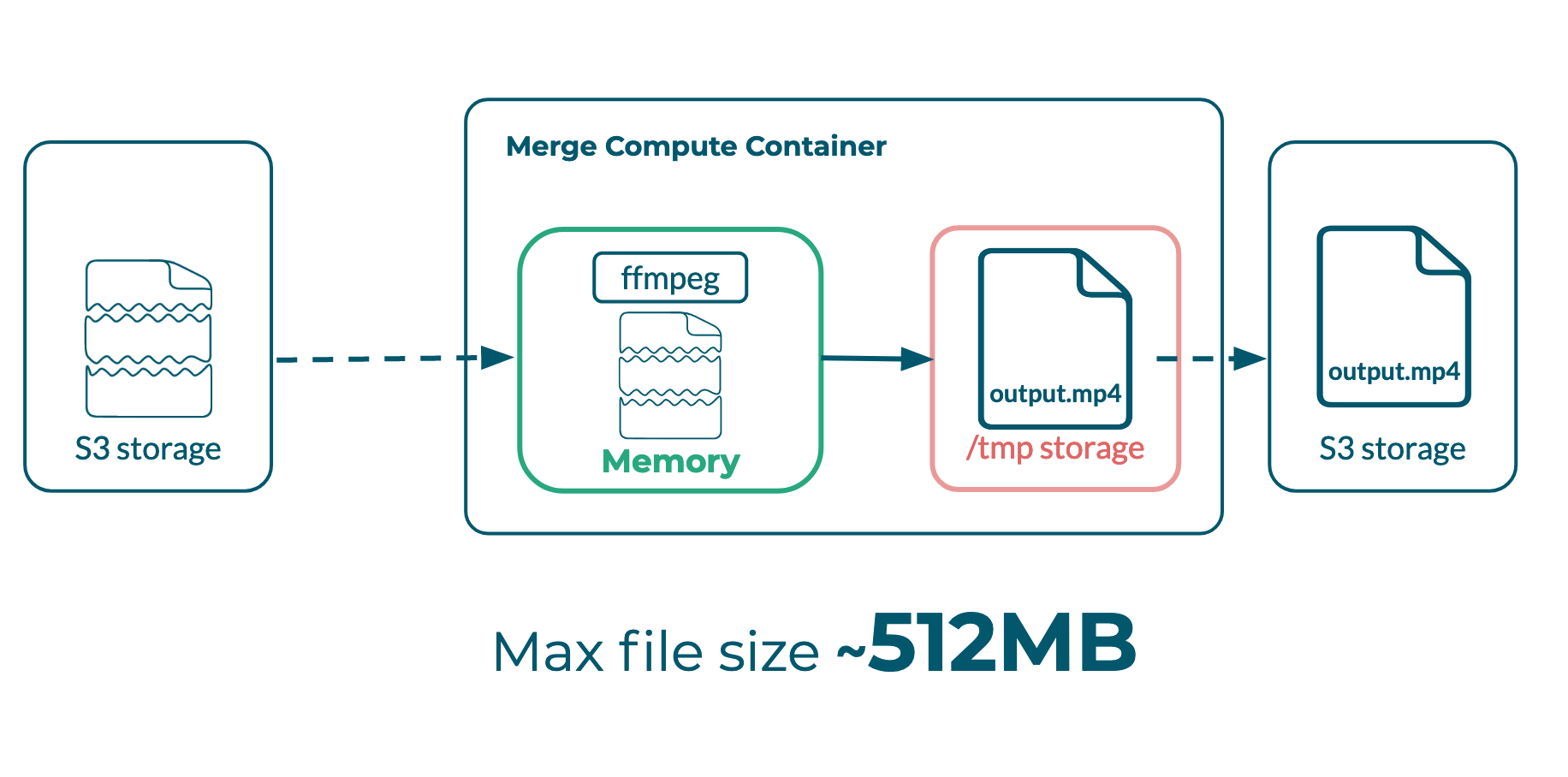
AWS Lambda functions execute in sandboxes, also referred to as containers, that isolate them from other functions. Each Lambda container is allocated with a set of resources, including 512 megabytes of temporary local storage. This storage proved useful while prototyping our pipeline; early versions of Bento stored entire video files in temporary local storage during the Transcoder and Merger stages. The local files were used as input for Ffmpeg’s processes, and the output files were then uploaded to S3 for permanent storage.
However, as we moved deeper into development, we found that processing entire video files locally created a bottleneck: the size of videos that Bento could support was capped by Lambda’s limited local storage.
Let’s zoom into how this problem manifested in the Merge function, and what we did to resolve it.
In our first implementation, the Merger function retrieved transcoded video segments from S3 and saved them to the instance’s temporary local storage. FFmpeg concatenated these segments into a complete video and stored the output file in the same local storage.
At this point, the local storage demand for a given instance of the Merger function was around double the size of the final video (the size of all the individual segments + the size of completed video).
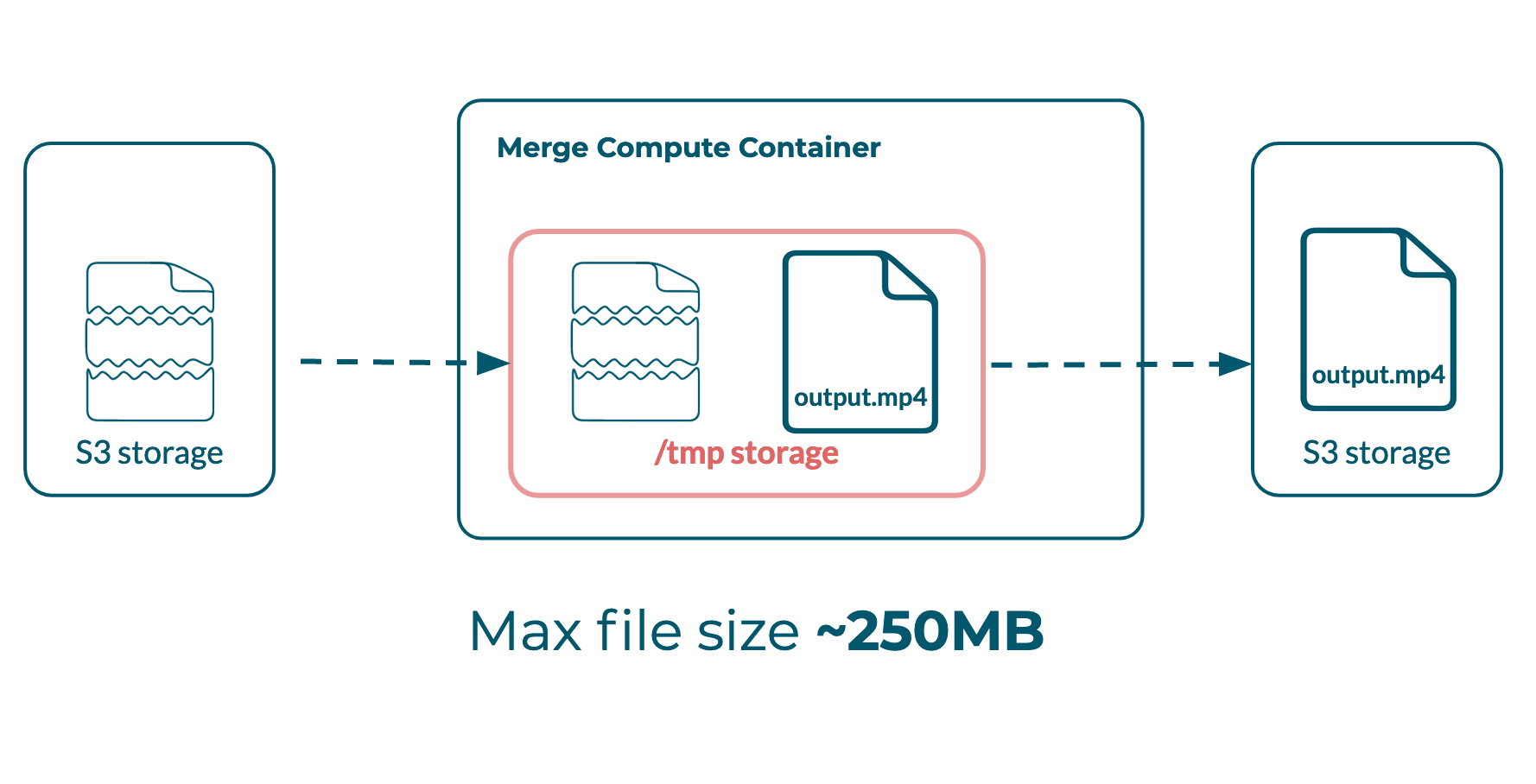
Problem: both the segments and the final video were living in temporary storage before the final video could be moved to S3
Given the 512 MB limit of local storage, this means that the absolute ceiling on the file size of any video running through the Bento pipeline was 256 MB. In practice, videos greater than 200MB routinely hit our storage limit, as temporary storage may also possess artifacts from previous function executions.
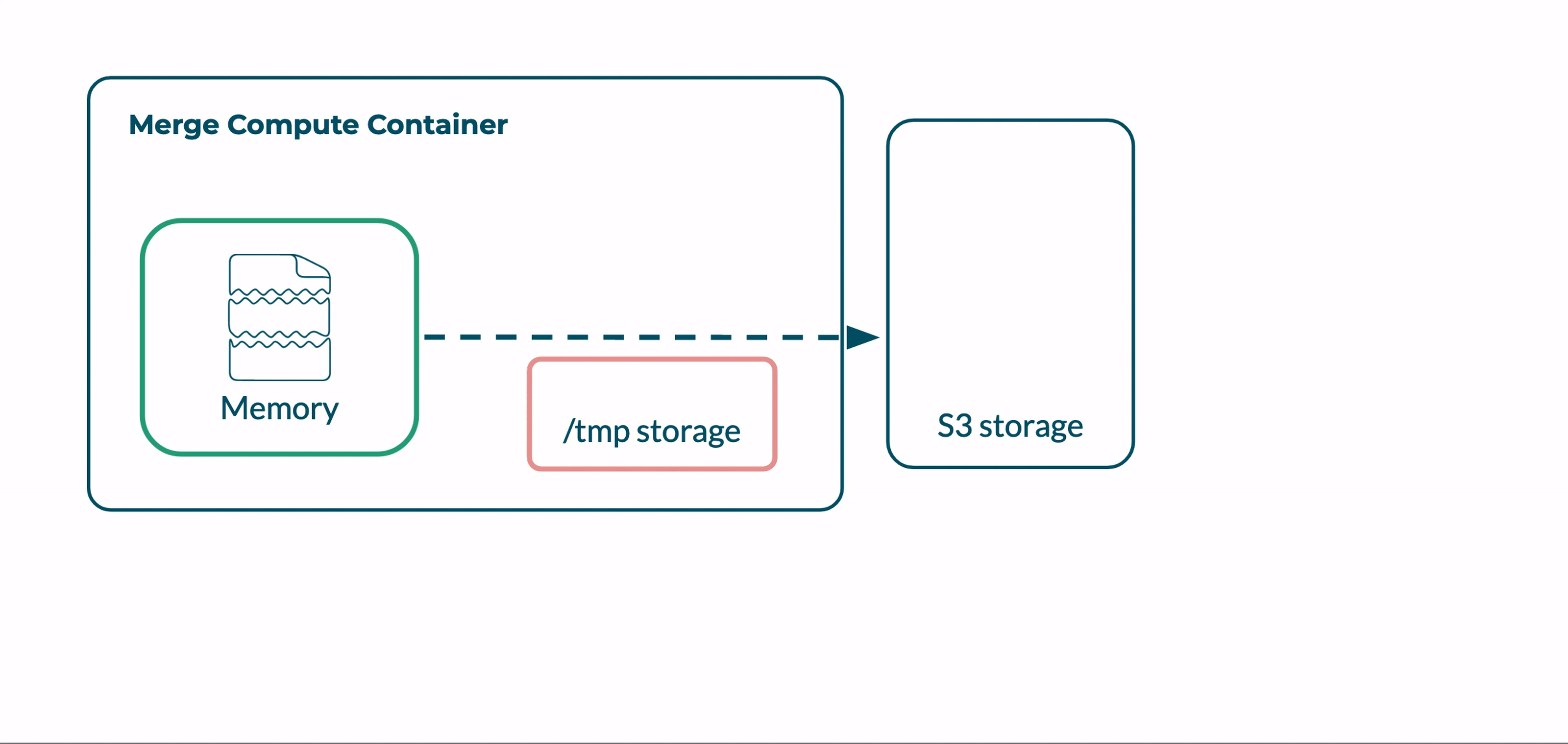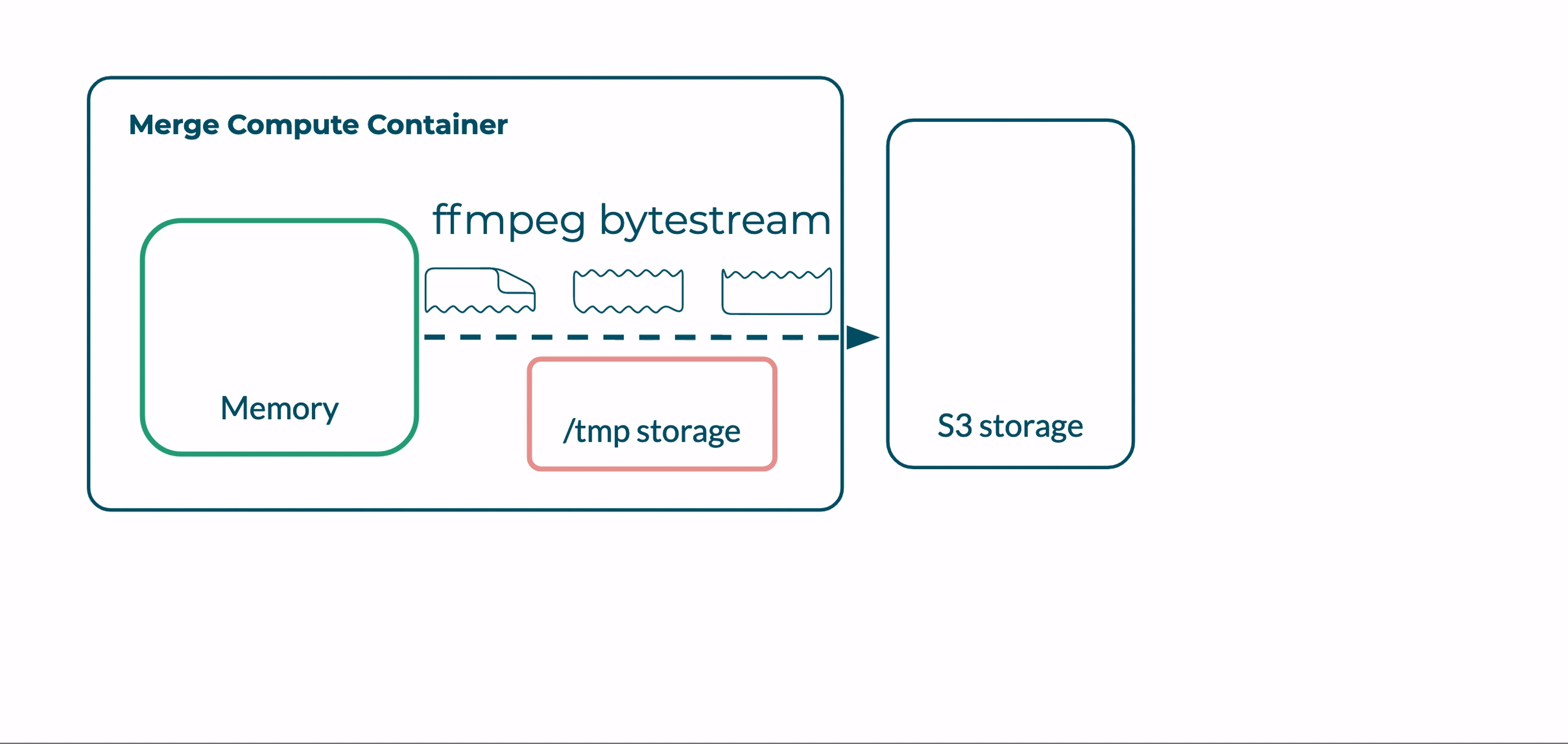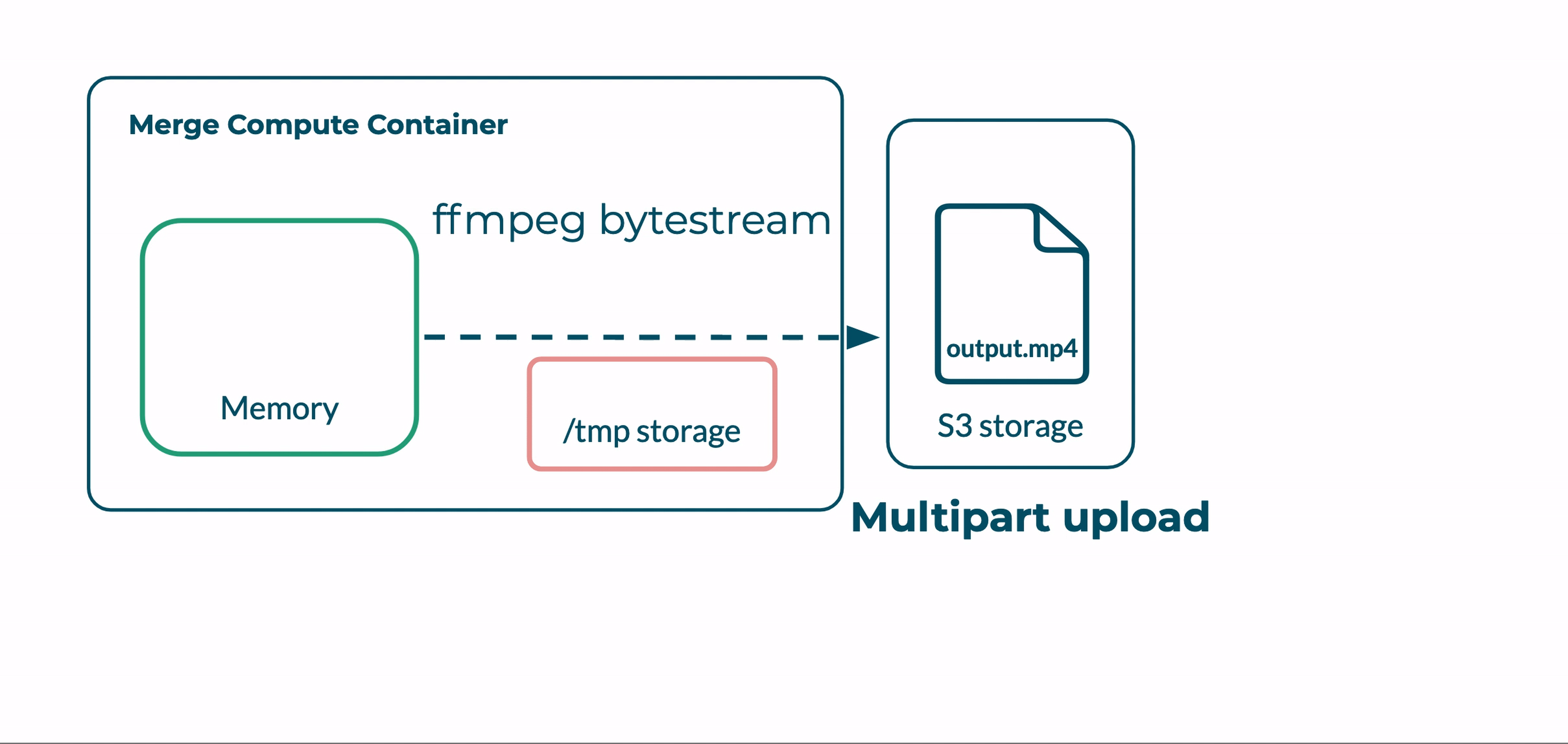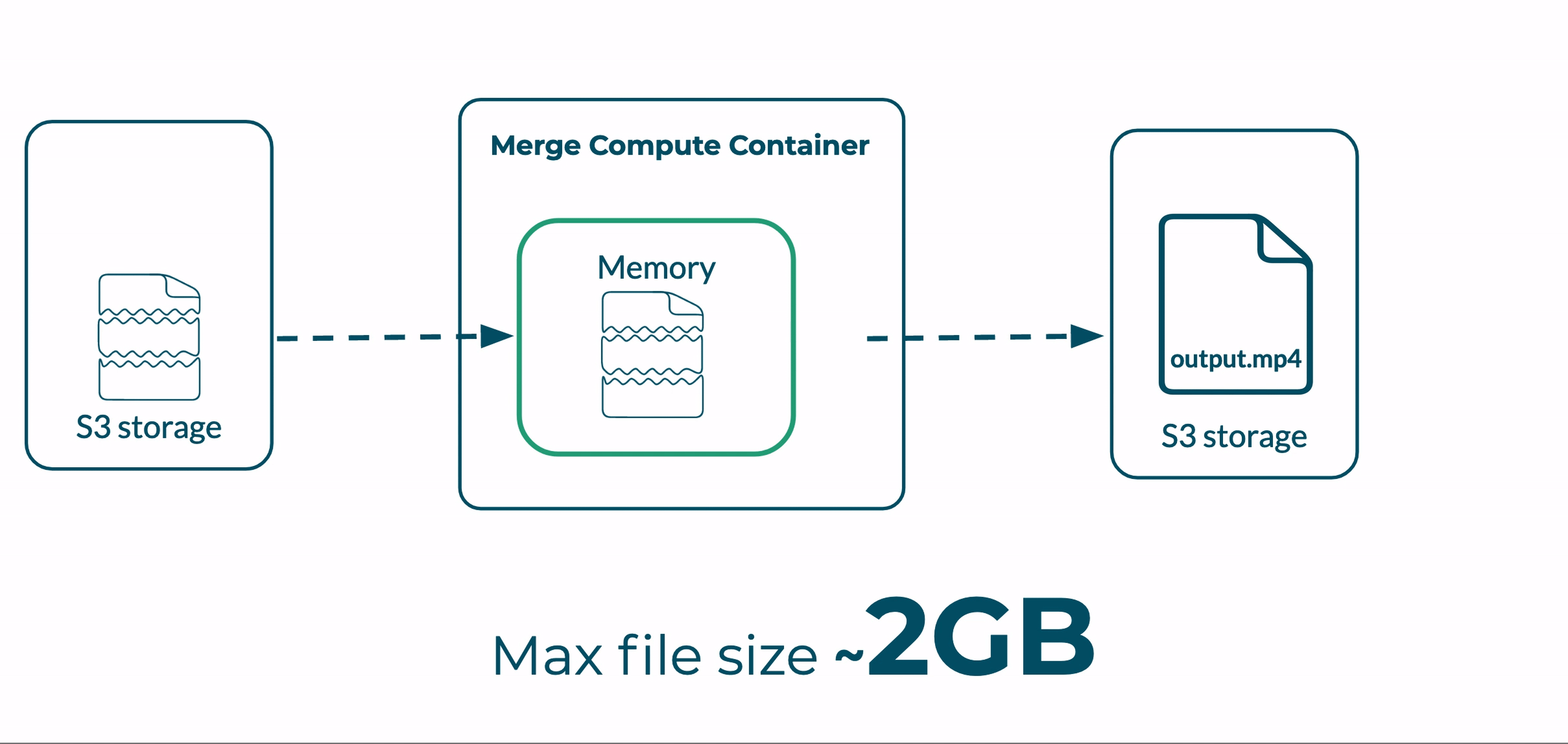
The first problem we had to solve was concatenating the video segments without downloading each segment to temporary storage. Ffmpeg’s ability to accept file input over HTTP provides part of the solution.
As we describe in section 6.2, FFmpeg accepts file input both locally and via HTTP. When HTTP is used as an input source, FFmpeg retrieves ranges of a video file over HTTP and processes them in memory.
During the concatenation step of our Merge function, we provide Ffmpeg with a list of URLs that point to each segment’s location in S3 storage. Ffmpeg processes each remote segment using HTTP input and joins the segments into a completed video, which is saved to temporary local storage.
Final video in temporary storage before being moved to S3
Following the change to HTTP input, we now held a single file, the complete transcoded video, in temporary local storage. Our file size ceiling increased to roughly 512 MB - the local storage limit of the function container.
Doubling our file size capacity is a good start, but 512 MB is relatively small in the world of video files. We needed to do more work to expand our use case beyond this storage limit.
By default, FFmpeg outputs processed videos to local storage. Our challenge was now developing a function that would accept input over HTTP, concatenate files in memory, and output the result to a remote server.
We explored whether it was possible to have FFmpeg output a completed video directly to S3 storage.
We discovered that FFmpeg outputs processed files as a byte stream that can be directly accessed via the FFmpeg process’ stdout. Ordinarily, this byte stream is written to a local file. However, using native bash commands, we can pipe this output to any other stdin.
FFmpeg output piped as a byte stream to S3
To take advantage of this, we required a tool to interact with AWS services via bash. The AWS Command Line Interface (CLI) solves this problem by allowing us to interact with AWS services from the command line.
The storage limitations of Lambda containers meant that we couldn’t install the AWS CLI binary directly to a function’s container. We decided to use AWS Lambda Layers to provide the Merger function with access to the CLI. Lambda Layers are a feature that enable users to deploy additional libraries and dependencies that are available to any Lambda function.
We now had a means of piping Ffmpeg output directly to S3. S3’s support for multipart uploads enables the final step in this process. Multipart uploads are a feature provided by Amazon S3. They enable clients to transfer files in chunks that the server can receive in any order. The chunks are assembled into the full file by the server when the transfer is complete. Multipart uploads are the default file transfer protocol for large uploads to S3 via AWS CLI.
We were now able to take input segments via HTTP, concatenate them in memory, and pipe the completed file directly to S3 as a byte stream, which was transferred in chunks and delivered using multipart uploads.
By implementing this process to avoid local Lambda storage, we removed our file size ceiling of 512 MB. The Bento pipeline could now support multi-gigabyte files.
Our transcoded videos now lived in S3 storage. However, when we tested our new files, we ran into playback issues. Some videos would only play for a few seconds in certain media players, while in others they would play in full.
This issue stemmed from an issue with metadata attached to the transcoded files. MP4 videos have a small bit of metadata written to them, which media players and other video software may use in the course of playback.
Ordinarily, Ffmpeg writes this metadata to the video at the end of the transcoding process, but it appends it to the beginning of the transcoded file.
The problems we were experiencing were caused by our output of transcoded files to a remote server. When Ffmpeg concatenates a video file, it does so roughly from beginning to end. This meant that we were transferring the beginning chunks of the completed file to S3 before Ffmpeg had completed its processing.
When Ffmpeg reached the end of the transcoding process, it tried to seek back to the beginning of the file to write the metadata. However, because the file was not stored locally, Ffmpeg no longer had access to the beginning of the file, and the metadata was not written. As a result, media players that relied on this metadata had playback issues.
To find a solution, we tested whether the mere existence of a metadata object in the video file was the issue, rather than the specific content of the metadata. If simply providing ‘empty’ metadata to the video was sufficient for affected media players, then we could resolve the problem.
Ffmpeg accepts a command to attach empty metadata to the beginning of video files at the start of processing. When our Merge function performs its concatenation step, this command prepends empty metadata to the initial chunk of the completed video before sending the chunk to S3. As a result, Ffmpeg does not try to seek back and update that chunk when concatenation is complete.
We found that this technique resolved our playback issue. Transcoded videos successfully played across media players.
In our initial approach to Bento, both the transcoded segments and the final video were stored in a Merger function’s temporary local storage before being moved to S3. This set an effective limit on the size of videos that Bento could transcode to under 200 megabytes.
Following our changes, transcoded segments are processed in memory via HTTP input. The final video is transferred directly to S3, taking advantage of HTTP multipart uploads. To facilitate this process, we update the typical way that metadata is written to MP4 files.
In aggregate, these improvements raise Bento's maximum supported file size from under 250 megabytes to over 2 gigabytes.
The Bento Pipeline is deployed straight to an Amazon Web Services account. Once the pipeline is deployed, a user can begin transcoding videos if they are comfortable interacting directly with AWS resources via the AWS CLI or AWS web console. To make Bento simple to use for everyone, we also developed an admin dashboard that users can launch to enjoy all the features of their pipeline with a simple point and click interface. We call this the Bento Dashboard.
Deploying a new pipeline involves creating a number of AWS resources (primarily Lambda functions, DynamoDB tables, and S3 buckets) as well as the various permissions necessary to allow these resources to interact with each other.
Ordinarily, this can be a lengthy process, especially for those who do not have experience working with AWS. Bento automates and streamlines this process to five main steps.
We used the Serverless framework to enable the creation of all of the AWS resources and most of the necessary configurations with a single command. This open source framework is designed to facilitate serverless application deployment. Serverless follows deployment instructions that are specified within a yaml file.
Bento Dashboard provides a simple interface to transcode videos
The Bento Dashboard ensures users can easily use their pipeline. Bento Dashboard is built in React with an Express backend that can be run locally for individual use, or deployed to Amazon EC2 for organizational use.
Deploying the Dashboard backend is a four step process.
We use Docker to containerize the Express app for easy deployment on EC2 or any other cloud computing platform. Bento users also have the option to deploy on their local machine. The Docker image will ensure the app runs consistently wherever it is deployed.
The front end of the dashboard is built with React. Bento users that want to share access to their pipeline across a team or organization can follow our instructions to host the React files on S3. Otherwise, users have the flexibility to simply run the React app locally.
We’d like to highlight some opportunities to enhance Bento that we’re excited about.
Bento currently supports MP4 output because it is the most widely used and supported video file format in use today.
We’d like to add support for HLS and DASH formats, which together represent the most common adaptive bitrate streaming formats. Adaptive bitrate streaming is a technique employed by modern video players that enable on-the-fly quality adjustments to changes in available bandwidth.
Many businesses perform additional transformations to their videos, including adding subtitles and intro/outro bumpers. Bento’s transcoding pipeline is well-suited to be extended to perform these sorts of transformations.
We are looking forward to new opportunities. Please contact us if this project interested you, or if you have any questions!

Toronto, ON

Los Angeles, CA

Tulsa, OK